漢藏語系,是世界第二大語系,也是一個相對獨特的語系:漢藏語系呈現明顯的漢-藏緬二分格局,其型別學之豐富度是其它語系中不曾見到的;大多數漢藏語都有先後演化出來的形態和詞綴,在語法上明顯靠近東南亞語言,一個半音節加顯著的字首-中綴偏好;漢藏語人群在基因上面也接近東南亞語言使用人群,尤其是南亞語和苗瑤語人群。
但是漢藏語系的基本詞匯來源卻很少與南方諸語言有關聯,反而和分布於北歐-西伯利亞的烏拉爾語系關系密切,這在周圍的東亞語言當中都找不到類似案例。
那麽,什麽導致了漢藏語系出現「詞匯烏拉爾,語法東南亞」的獨特現象呢?
目前筆者猜想該現象出現的原因和2萬多年前曾在黃河中下遊駐留的N父系單倍群以及人群遷移有關系,而且這個現象的產生還有某一人群學了另一人群語言的原因。
神秘莫測的Y-N單倍群:粟作文化創始者,部份下遊支系(主要是N1a-M128)被漢藏專屬O-M134擊敗北上
漢藏語系在形成之前,被認為和漢藏語系相關的人群——O2-M122、N-M231等人群很早就開始在中國中原地區紮根。
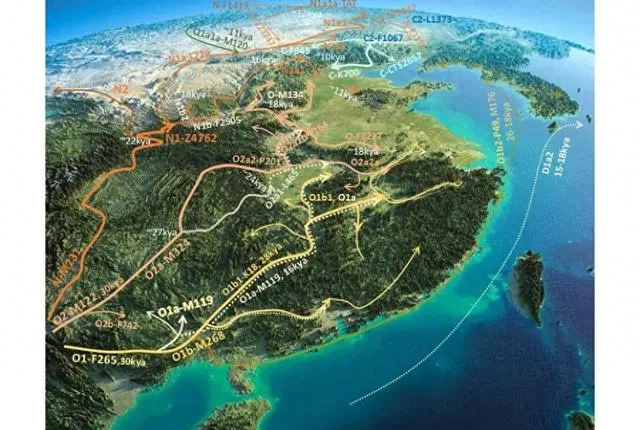
古代NO系人群遷移的路線,圖源來自知乎使用者@老犀牛。
在距離當今的三萬多年前,中原大地上曾經有三批人群遷入,其中O1人群沿著東南沿海地區北上,O2則沿川渝地區北上,N-M231則是沿著原來的藏緬走廊北上:
O1-F265是第一批遷入中原大地的先民,約在32690年前遷入中原。而O2-M122在29460年前遷入中原,最年輕的N-M231則在23530年前遷入中原。——知乎使用者拓撲維度
和漢藏語系高度相關的N-M1819,就是Y-N-M231的下遊。
而在32000多年前的以O1a-M119占主體的南島群體和O1b-M268這兩支最開始居住在東亞的人群並沒有感覺到異常情況,仍然很安逸的生活在黃淮海平原以及中原地區。
隨後,和Y-O1人群分化近三萬年的O2-M122從川渝地區北上N-M231,逐漸從江淮北上,擊敗並驅散了原有的Y-O1單倍群,使得原先的O1單倍群逐漸遷徙到大陸南方、台灣島,甚至還有一部份往太平洋上移動。
至於另一部份沒有來得及遷徙的父系單倍群為O1的前南島和前南亞人群則融入前漢藏語的人群,塑造了漢藏語的底層,並在接觸的過程中加強了底層的影響:喜歡使用字首和中綴,重音節靠後;部份漢藏語如景頗語、珞巴語、嘉絨語都是典型的一個半音節語言。
N-M231在前往中原地區以及黃河以北後,創立了粟作文化,而漢藏語系人群的粟作文化可能就和這群人有關。

粟作文化人群的作物:小米,圖源來自百度使用者@蝌蚪五線譜。
而在N-M231建立粟作文化前的6000多年前,O2a-M122就已經在中原地區生活了。俗話說得好:近水樓台先得月。自然在中原地區的O2a-M 122是最先接觸到粟作文化並行揚光大的一群人。
在接觸粟作文化的過程中,O2-M122學習種植小米之後逐漸壯大。
之後在19000多年前的中國大陸,N1a-F1206因為打不過興起的O2a-M122遷移到北亞,N1b-F2480和少量的N1a人群融入O2-M122。
然後又過了近一萬年,漢藏語系誕生。
在漢藏語系誕生前,O2a-M122人群有大機率將N-M231的語言和詞匯學走了。
也就是說,漢藏語系的誕生,其實是多個單倍群融入而導致的結果,其中被擊敗的單倍群有部份成了漢藏的語言文化底層,而且其中的N-M231以及N1a等單倍群還可能構成了先進者效應,這個過程是很難說清的。
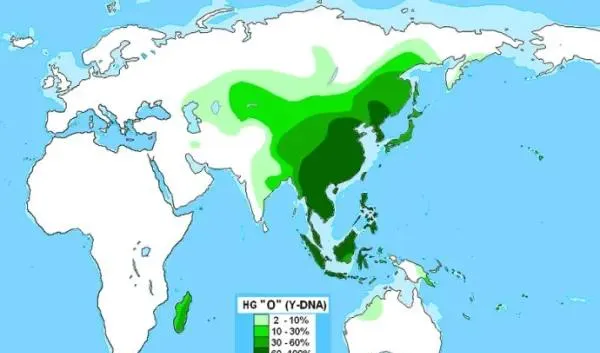
Y-O人群的分布。
也許在這一段史前的時間段內,漢藏人群和遷移沒多遠的烏拉爾人群有長時間的交流和接觸,包括但不限於物質方面的接觸和文化方面的接觸,因此在漢藏語系誕生之前就已經湧入了大量烏拉爾語系詞匯,並成了漢藏語的底層。
漢藏語系單有的N1b單倍群,在烏拉爾語系人群當中也存在,然而N1a和N1b實際上分化超過2萬年,未必站得住腳
雖然說N1b是漢藏語人群的重要基因之一,但並不代表N1b基因僅僅在漢藏語人群中有分布。
N1b父系單倍群除了在黃河流域有所分布以外,在北極附近的涅涅茨地區也有所分布。
也就是說:N1b雖然是N南支,但仍然有可能使用烏拉爾語。
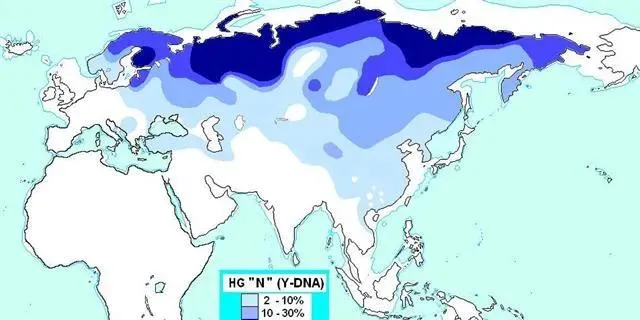
Y-N的分布。
因此分子人類學上來講,似乎也支持漢藏語和烏拉爾語共祖。
然而,我們需要清楚的是,N1b和N1a之間分化已接近2萬年,就算分子人類學上支持漢藏和烏拉爾共祖,在語言學上幾乎也站不住腳了。
那只能說明:Y染色體為N1b的人群可能在某一時間點學習了烏拉爾語並根據自身語言特點進行了演變和改造。
語言未必會跟隨基因,分子人類學無法完全且準確的和語言進行對應。
另一方面能解釋漢藏語系雖然東南亞語言的特征比較多,但詞匯接近烏拉爾語的角度是:語言未必會和基因一一對應,無論是Y染色體也好還是體染色體也罷,都無法準確的與語言對應。
到目前為止,除了印歐語系與其父系單倍群R1a或R1b有高度對應之外,其余的語系基本上都是幾群人混合產生的,有輕重不等的凱瑞奧爾化傾向。
而且即使是同一個單倍群人群,說的語言也不一定親近。
譬如南亞語系人群和苗瑤語系人群均共享O3a3b-M7單倍群(目前歸並為O2a3b-M7),但是苗瑤語系和南亞語系偏偏就不同源,即使列舉出來部份同源詞幾乎也不是規律演化來的。

苗瑤語系和南亞語系的共享單倍群,圖源B站使用者@Arounsausdei
相反,苗瑤語系和漢藏語相關的詞匯反而更多,雖然說O2a-M117和O2a3b-M7分化的時間也很早。
類似的還有突厥語系,和烏拉爾語系共享N1a-F4205單倍群基因,但二者的關系同樣疏遠到不可靠。
而漢藏和烏拉爾則正好與上述所提及的這幾個語言相反,在漢藏語裏面的部份詞匯與烏拉爾語的對應詞匯是存在規律音變對應的,比如漢藏語系當中常常m開頭的詞匯,到烏拉爾語裏面就會丟掉m,且烏拉爾語系語言當中的詞匯,提前把韻尾遺失;漢藏語的送氣音,可能來自於第一輔音和第二個送氣輔音的結合。

另一個例子是土耳其人,雖然大多數人Y單倍群和希臘的J同源,且體染色體也和希臘人相近,但仍然使用突厥語。
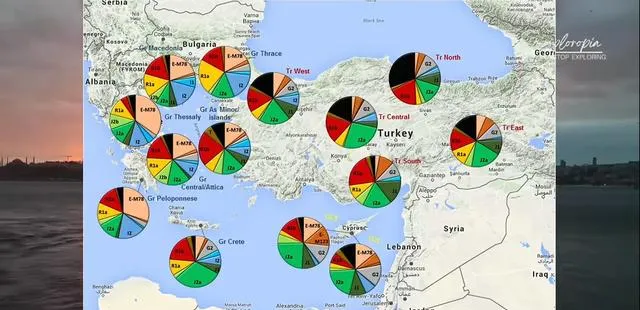
突厥人基因
還有一個例子是巴斯克人,雖然說Y單倍群、體染色體單倍群都和印歐人一模一樣,但仍然保留了巴斯克語。
那麽,這兩個案例就可以解釋漢藏語和烏拉爾語之間的關系了。
O2a-M122人群,有可能最開始既不講漢藏語,也不說烏拉爾語,而是類似於南亞語和苗瑤語的一類語言。
但最後因為某種原因(粟作文化)而產生了文化或語言的認同,而改說了烏拉爾語,最後再根據自身語言的特點,而形成漢藏語。
因此,基於大多數語系的產生是多個Y單倍群人群混合導致的情況來看,語系和語系之間是否同源其一是內部影響(先進者效應),其二則是某一民族改學了另一門語言。
結語
漢藏語系語法特征接近東南亞,詞源接近烏拉爾語系確實是件很奇妙的事,原因復雜且多樣,值得深入研究。
本人提出的只是關於基因和民族遷徙方面的,另一個角度其實可以從地理角度討論,本篇就不再贅述了。











