CPU和GPU之所以大不相同,是由於其設計目標的不同,它們分別針對了兩種不同的套用場景。
CPU需要很強的通用性來處理各種不同的數據型別,同時又要邏輯判斷又會引入大量的分支跳轉和中斷的處理。這些都使得CPU的內部結構異常復雜。
而GPU面對的則是型別高度統一的、相互無依賴的大規模數據和不需要被打斷的純凈的計算環境。
於是CPU和GPU就呈現出非常不同的架構(示意圖):
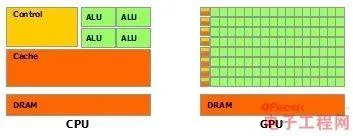
其中綠色的是計算單元,橙紅色的是儲存單元,橙黃色的是控制單元。
GPU采用了數量眾多的計算單元和超長的流水線,但只有非常簡單的控制邏輯並省去了Cache。
而CPU不僅被Cache占據了大量空間,而且還有復雜的控制邏輯和諸多最佳化電路,相比之下計算能力只是CPU很小的一部份。
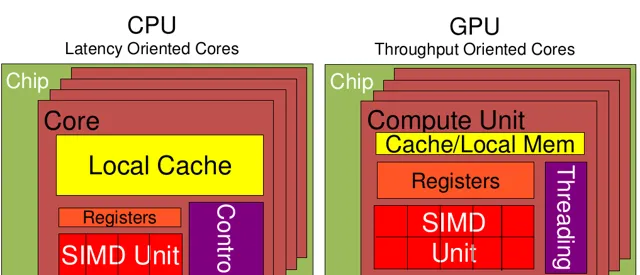
從上圖可以看出:
Cache,local memory:CPU > GPU
Threads(執行緒數):GPU > CPU
Registers:GPU > CPU 多寄存器可以支持非常多的Thread,thread需要用到register,thread數目大,register也必須得跟著很大才行。
SIMD Unit(單指令多數據流,以同步方式,在同一時間內執行同一條指令):GPU > CPU。
CPU 基於低延時的設計:
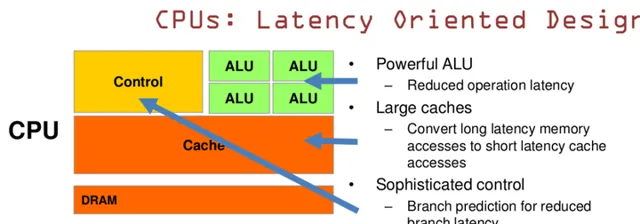
CPU有強大的ALU(算術運算單元),它可以在很少的時鐘周期內完成算術計算。
當今的CPU可以達到64bit 雙精度。執行雙精度浮點源算的加法和乘法只需要1~3個時鐘周期。
CPU的時鐘周期的頻率是非常高的,達到1.532~3gigahertz(千兆HZ, 10的9次方)。
大的緩存也可以降低延時。保存很多的數據放在緩存裏面,當需要存取的這些數據,只要在之前存取過的,如今直接在緩存裏面取即可。
復雜的邏輯控制單元。當程式含有多個分支的時候,它透過提供分支預測的能力來降低延時。
數據轉發。當一些指令依賴前面的指令結果時,數據轉發的邏輯控制單元決定這些指令在pipeline中的位置並且盡可能快的轉發一個指令的結果給後續的指令。這些動作需要很多的對比電路單元和轉發電路單元。
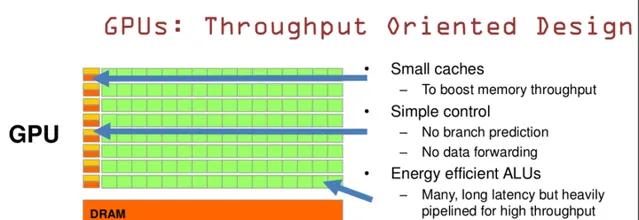
GPU是基於大的吞吐量設計。
GPU的特點是有很多的ALU和很少的cache。緩存的目的不是保存後面需要存取的數據的,這點和CPU不同,而是為thread提高服務的。如果有很多執行緒需要存取同一個相同的數據,緩存會合並這些存取,然後再去存取dram(因為需要存取的數據保存在dram中而不是cache裏面),獲取數據後cache會轉發這個數據給對應的執行緒,這個時候是數據轉發的角色。但是由於需要存取dram,自然會帶來延時的問題。
GPU的控制單元(左邊黃色區域塊)可以把多個的存取合並成少的存取。
GPU的雖然有dram延時,卻有非常多的ALU和非常多的thread。為了平衡記憶體延時的問題,我們可以中充分利用多的ALU的特性達到一個非常大的吞吐量的效果。盡可能多的分配多的Threads。通常來看GPU ALU會有非常重的pipeline就是因為這樣。
所以與CPU擅長邏輯控制,序列的運算。和通用型別數據運算不同,GPU擅長的是大規模並行計算,這也正是密碼破解等所需要的。所以GPU除了影像處理,也越來越多地參與到計算當中來。
GPU 的工作大部份就是這樣,計算量大,但沒什麽技術含量,而且要重復很多很多次。就像你有個工作需要算幾億次一百以內加減乘除一樣,最好的辦法就是雇上幾十個小學生一起算,一人算一部份,反正這些計算也沒什麽技術含量,純粹體力活而已。而CPU就像老教授,積分微分都會算,就是薪資高,一個老教授資頂二十個小學生,你要是富士康你雇哪個?
GPU 就是這樣,用很多簡單的計算單元去完成大量的計算任務,純粹的人海戰術。這種策略基於一個前提,就是小學生A和小學生B的工作沒有什麽依賴性,是互相獨立的。很多涉及到大量計算的問題基本都有這種特性,比如你說的破解密碼,挖礦和很多圖形學的計算。這些計算可以分解為多個相同的簡單小任務,每個任務就可以分給一個小學生去做。但還有一些任務涉及到「流」的問題。比如你去相親,雙方看著順眼才能繼續發展。總不能你這邊還沒見面呢,那邊找人把證都給領了。這種比較復雜的問題都是CPU來做的。
總而言之 ,CPU和GPU因為最初用來處理的任務就不同,所以設計上有不小的區別。而某些任務和GPU最初用來解決的問題比較相似,所以用GPU來算了。GPU的運算速度取決於雇了多少小學生,CPU的運算速度取決於請了多麽厲害的教授。教授處理復雜任務的能力是碾壓小學生的,但是對於沒那麽復雜的任務,還是頂不住人多。當然現在的GPU也能做一些稍微復雜的工作了,相當於升級成初中生高中生的水平。但還需要CPU來把數據餵到嘴邊才能開始幹活,究竟還是靠CPU來管的。
什麽型別的程式適合在GPU上執行?
(1)計算密集型的程式。所謂計算密集型(Compute-intensive)的程式,就是其大部份執行時間花在了寄存器運算上,寄存器的速度和處理器的速度相當,從寄存器讀寫數據幾乎沒有延時。可以做一下對比,讀記憶體的延遲大概是幾百個時鐘周期;讀硬碟的速度就不說了,即便是SSD, 也實在是太慢了。
(2)易於並列的程式。GPU其實是一種SIMD(Single Instruction Multiple Data)架構, 他有成百上千個核,每一個核在同一時間最好能做同樣的事情。
文章轉載自:Magnum Programm Life










