摘要
本文基於最新的基於深度學習的目標檢測演算法 (YOLOv5、YOLOv6、YOLOv8)以及YOLOv9) 對紅外行人車輛數據集進行訓練與驗證,得到了最好的模型權重檔。使用Streamlit框架來搭建互動式Web套用界面,可以在網頁端實作模型對影像、視訊和即時網路攝影機的目標檢測功能,在網頁端使用者可以調整檢測參數(IoU、檢測置信度等)。本數據集標註了 行人和車輛這兩個類別,且已轉換成YOLO格式的標註檔。
(註:本文包含三個不同的系統變體
【1】基於YOLOv8和Streamlit框架的目標檢測演算法(Ultralytics版本為8.0),源碼和數據集連結:https://mbd.pub/o/bread/ZpeTmJlt
【2】基於YOLOv8和YOLOv5和Streamlit框架的目標檢測演算法(Ultralytics版本為8.0,YOLOv5的版本為7.0,源碼和數據集連結:https://mbd.pub/o/bread/ZpeTmJls
【3】基於YOLOv5、6、8、9和Streamlit框架的目標檢測演算法(Ultralytics版本為8.2),源碼和數據集連結:https://mbd.pub/o/bread/ZpeTmJlp
環境搭建
l 開啟Anaconda prompt (管理員開啟)
l 進入計畫目錄:cd xxxxxxxx (如果在非c盤,需要先f: (以f盤為例))
l 建立一個conda虛擬環境:conda create -n st python=3.10
l 進入虛擬環境:conda activate st
l 安裝依賴環境:pip install -r requirements.txt、
l 登入時預設的使用者名稱為111,密碼也為111
計畫開啟:(無登入界面,預設使用CPU檢測):streamlit run app.py
(無登入界面,預設使用GPU檢測):streamlit run app_gpu.py
(有登入界面,預設使用CPU檢測):streamlit run login.py
(有登入界面,預設使用GPU檢測):streamlit run login_gpu.py
YOLO演算法綜述
YOLO(You Only Look Once)系列演算法是一系列用於即時目標檢測的深度學習演算法,由Joseph Redmon等人開發。該系列演算法的主要思想是將目標檢測問題轉化為單一的回歸問題,透過一個神經網路直接從整幅影像中輸出目標的類別和邊界框座標,從而實作快速準確的目標檢測。YOLO系列演算法的主要版本包括YOLO、YOLOv2、YOLOv3、YOLOv4、YOLOv5、YOLOv6、YOLOv7、YOLOv8和YOLOv9等,每個版本都在前一版本的基礎上進行了改進和最佳化,以提高檢測精度和速度。下面將詳細介紹每個版本的特點和改進。
l YOLO(You Only Look Once):它將目標檢測問題轉化為一個單一的回歸問題,並透過一個摺積神經網路直接輸出目標的類別和邊界框座標。YOLO將影像分割為 S × S 個格子(grid),每個格子負責檢測該格子內的目標,並輸出目標的類別機率以及邊界框的位置資訊。由於采用單一網路直接輸出結果,YOLO在速度上具有優勢,但在小目標檢測和定位精度上存在一定問題。
l YOLOv2:YOLOv2在YOLO的基礎上進行了改進和最佳化,主要包括使用更深的網路結構(Darknet-19)、采用多尺度預測和Anchor Boxes等技術。多尺度預測可以提高模型對不同尺度目標的檢測能力,Anchor Boxes可以更好地適應不同形狀的目標,並提高定位精度。此外,YOLOv2還引入了批標準化(Batch Normalization)和摺積替代池化(Convolutional With Pooling)等技術來提高模型的訓練速度和精度。
l YOLOv3:YOLOv3在YOLOv2的基礎上進一步改進,主要包括引入殘留誤差網路(ResNet)作為主幹網路、采用多尺度預測以及使用更細粒度的Anchor Boxes等技術。引入ResNet可以提高模型的特征提取能力,多尺度預測可以進一步提高模型對不同尺度目標的檢測能力,使用更細粒度的Anchor Boxes可以提高模型的定位精度。此外,YOLOv3還采用了特征融合和跨尺度連線等技術來提高模型的檢測效能。
l YOLOv4:YOLOv4是YOLO系列演算法的最新版本,它在YOLOv3的基礎上進行了進一步的改進和最佳化,主要包括引入更深更寬的網路結構(CSPDarknet53)、采用更多的數據增強和正則化技術以及使用更大的Batch Size等。CSPDarknet53是一種全新的網路結構,可以提高模型的特征提取能力和泛化能力,更多的數據增強和正則化技術可以進一步提高模型的魯棒性和泛化能力,使用更大的Batch Size可以提高模型的訓練速度和穩定性。此外,YOLOv4還引入了模型融合和跨域訓練等技術來進一步提高模型的檢測效能。
l YOLOv5:YOLOv5 是由ultralytics團隊開發的目標檢測演算法,透過簡化模型結構和最佳化訓練流程,實作了更快的訓練速度和更高的檢測精度。YOLOv5采用了CSPDarknet53作為骨幹網路,采用了CSP(Cross Stage Partial)結構,提高了模型的效率和準確性。YOLOv5引入了自適應訓練策略,可以根據硬體資源自動調整訓練超參數,提高了模型的泛化能力。YOLOv5具有多尺度訓練和推理的能力,可以在不同大小的目標上取得良好的檢測效果。
l YOLOv6:YOLOv6 是美團視覺智慧部研發的一款目標檢測框架,致力於工業套用。本框架同時專註於檢測的精度和推理效率,在工業界常用的尺寸模型中:YOLOv6-nano 在 COCO 上精度可達 35.0% AP,在 T4 上推理速度可達 1242 FPS;YOLOv6-s 在 COCO 上精度可達 43.1% AP,在 T4 上推理速度可達 520 FPS。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,極大地簡化工程部署時的適配工作。
l YOLOv7:YOLOv7是一種優秀的端到端檢測演算法。YOLOv7由Alexey Bochkovskiy和Chien-Yao Wang等人(YOLOv4團隊)於2022年提出。在 5 FPS 到 120 FPS 的範圍內,YOLOv7 的速度和準確性都超過了所有已知的物體檢測器,在 30 FPS 的所有已知即時物體檢測器中,YOLOv7 的準確性最高,達到 56.8% AP。
l YOLOv8:YOLOv8 是 ultralytics 公司在 2023 年 1月 10 號開源的 YOLOv5 的下一個重大更新版本。是一款強大、靈活的目標檢測和影像分割工具,它提供了最新的 SOTA 技術。提供了一個全新的SOTA模型。基於縮放系數也提供了N/S/M/L/X不同尺度的模型,以滿足不同部署平台和套用場景的需求;網路結構上引入C2F和SPPF模組,並對不同尺度的模型進行了精心微調,提升網路特征提取能力及模型效能的同時,平衡模型的推理速度;采用Anchor-Free代替Anchor-Based,對網路輸出頭進行解耦,分離類別預測和目標框的回歸,同時去掉置信度分支;采用TaskAlignedAssigner 動態正樣本分配策略,提高樣本的生成品質;引入了 Distribution Focal Loss用於目標框的回歸。
l YOLOv9:YOLOv9引入了程式化梯度資訊(Programmable Gradient Information, PGI),這是一種全新的概念,旨在解決深層網路中資訊遺失的問題。傳統的目標檢測網路在傳遞深層資訊時,往往會遺失對最終預測至關重要的細節,而PGI技術能夠保證網路在學習過程中保持完整的輸入資訊,從而獲得更可靠的梯度資訊,提高權重更新的準確性。這一創新顯著提高了目標檢測的準確率,為即時高精度目標檢測提供了可能。
此外,YOLOv9采用了全新的網路架構——泛化高效層聚合網路(Generalized Efficient Layer Aggregation Network, GELAN)。GELAN透過梯度路徑規劃,最佳化了網路結構,利用傳統的摺積操作符實作了超越當前最先進方法(包括基於深度摺積的方法)的參數利用效率。這一設計不僅提高了模型的效能,同時也保證了模型的高效性,使YOLOv9能夠在保持輕量級的同時,達到前所未有的準確度和速度。在MS COCO這樣的挑戰性數據集上的驗證結果顯示,YOLOv9在目標檢測領域設定了新的效能基準,無論是在效率、速度還是準確性方面,YOLOv9都展示了卓越的效能
實驗數據集
系統使用的紅外行人車輛數據集手動標註了紅外行人車輛中行人和車輛這兩個類別,數據集總計8000張圖片。本文實驗的紅外行人車輛檢測辨識數據集包含訓練集6488張圖片,驗證集1512張圖片,選取部份數據部份樣本數據集如下圖所示。

關鍵技術
Streamlit
Streamlit 是一個開源應用程式框架,旨在簡化為機器學習和數據科學構建 web 應用程式的過程。近年來,它在套用 ML 社群中獲得了很大的吸重力。 Streamlit 成立於 2018 年,是前谷歌工程師在部署機器學習模型和儀表盤時遇到的挑戰所帶來的挫折。使用 Streamlit 框架,數據科學家和機器學習實踐者可以在幾個小時內構建自己的預測分析 web 應用程式。不需要依賴前端工程師或 HTML 、 CSS 或 Javascript 知識,因為這一切都是用 Python 完成的。一個簡單的Streamlit初始界面如下圖所示。
Streamlit的官方Github倉庫: https://github.com/streamlit/streamlit
Streamlit的官方文件: https://streamlit.io/
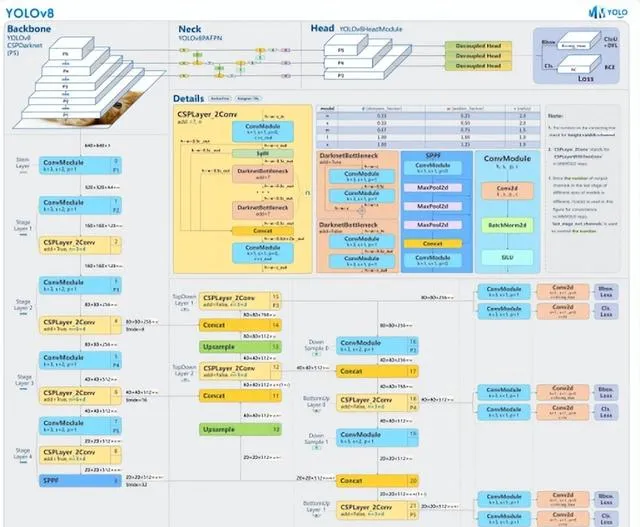
YOLOv8
YOLOv8 是 Ultralytics 公司在 2023 年 1月 10 號開源的 YOLOv5 的下一個重大更新版本,目前支持影像分類、物體檢測和例項分割任務,在還沒有開源時就收到了使用者的廣泛關註。YOLOv8 是一個 SOTA 模型,它建立在以前 YOLO 版本的成功基礎上,並引入了新的功能和改進,以進一步提升效能和靈活性。具體創新包括一個新的骨幹網路、一個新的 Ancher-Free 檢測頭和一個新的損失函式,可以在從 CPU 到 GPU 的各種硬體平台上執行。總而言之,Ultralytics 開源庫的兩個主要優點是:(1)融合眾多當前 SOTA 技術於一體;(2)未來將支持其他 YOLO 系列以及 YOLO 之外的更多演算法
YOLOv8 演算法的核心特性和改動可以歸結為如下:
l 提供了一個全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目標檢測網路和基於 YOLACT 的例項分割模型。和 YOLOv5 一樣,基於縮放系數也提供了 N/S/M/L/X 尺度的不同大小模型,用於滿足不同場景需求
l 骨幹網路和 Neck 部份可能參考了 YOLOv7 ELAN 設計思想,將 YOLOv5 的 C3 結構換成了梯度流更豐富的 C2f 結構,並對不同尺度模型調整了不同的通道數,屬於對模型結構精心微調,不再是無腦一套參數套用所有模型,大幅提升了模型效能。不過這個 C2f 模組中存在 Split 等操作對特定硬體部署沒有之前那麽友好了
l Head 部份相比 YOLOv5 改動較大,換成了目前主流的解耦頭結構,將分類和檢測頭分離,同時也從 Anchor-Based 換成了 Anchor-Free
l Loss 計算方面采用了 TaskAlignedAssigner 正樣本分配策略,並引入了 Distribution Focal Loss
YOLOv8官方Github:https://github.com/ultralytics/ultralytics
mmyolo官方參考資料: https://mmyolo.readthedocs.io/zh-cn/dev/recommended_topics/algorithm_descriptions/yolov8_description.html
YOLOv5
YOLOv5 是一個面向即時工業套用而開源的目標檢測演算法,受到了廣泛關註。讓 YOLOv5 爆火的原因不單純在於 YOLOv5 演算法本身的優異性,更多的在於開源庫的實用和魯棒性。簡單來說 YOLOv5 開源庫的主要特點為:
l 友好和完善的部署支持
l 演算法訓練速度極快,在 300 epoch 情況下訓練時長和大部份 one-stage 演算法如 RetinaNet、ATSS 和 two-stage 演算法如 Faster R-CNN 在 12 epoch 的訓練時間接近
l 框架進行了非常多的 corner case 最佳化,功能和文件也比較豐富
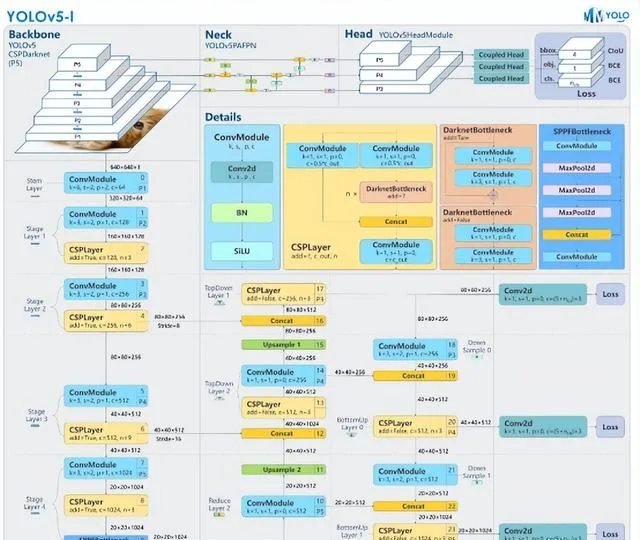
其他變體配置(n、s、m、x)與YOLOv5-l結構相同,唯一區別是模組數量與通道數
YOLOv5官方GitHub:https://github.com/ultralytics/yolov5
mmyolo官方資料: https://mmyolo.readthedocs.io/zh-cn/dev/recommended_topics/algorithm_descriptions/yolov5_description.html
YOLOv5封裝成一個類:
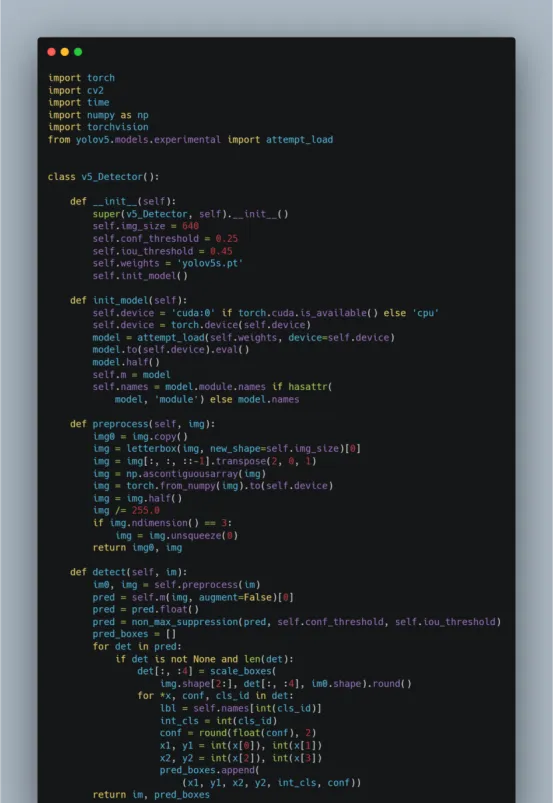
YOLOv9
摘要:當今的深度學習研究主要關註設計最佳目標函式,以實作模型預測與真實值的高度一致性,並開發合適的架構以確保預測過程中資訊的充分利用。然而,傳統方法往往忽視了在特征提取和空間轉換的多層處理過程中,輸入數據可能遭受的資訊損失問題。本研究深入探討了深度網路中數據傳遞過程中的資訊損失問題,特別是資訊瓶頸和可逆函式的挑戰。
提出了一種新概念——可編程梯度資訊(PGI),旨在解決深度網路處理復雜任務時遇到的資訊變化挑戰。透過PGI,可以在計算目標函式時保留完整的輸入資訊,從而提供準確的梯度資訊以最佳化網路權重。進一步地,本文設計了一種創新的輕量級網路架構,即廣義高效層聚合網路(GELAN),展示了PGI在提升輕量級模型效能方面的有效性。透過在MS COCO數據集上進行目標檢測任務的實驗驗證,證明了GELAN在參數效率方面超越了依賴深度可分摺積的現有技術。PGI的適用性跨越從輕量級到大型模型,能夠在無需大型預訓練數據集的條件下,實作從頭開始訓練模型的效能優勢。
PGI主要包括三個組成部份,即主分支、輔助可逆分支以及多級輔助資訊;PGI的推理流程僅涉及主分支,避免了額外推理成本的產生。這一設計精巧地應對了深度學習中的關鍵挑戰,透過兩個關鍵元件提升模型效能:
輔助可逆分支:引入此元件是為了解決隨著網路深度增加而引發的資訊瓶頸問題。這種資訊瓶頸會幹擾損失函式生成有效梯度的能力,輔助可逆分支透過保持資訊流動的完整性來克服這一障礙
多級輔助資訊:此部份旨在解決深度監督可能導致的誤差累積問題,尤其是在擁有多個預測分支的結構和輕量級模型中。透過引入多級輔助資訊,模型能夠更有效地學習並減少誤差傳播
Generalized ELAN:GELAN是透過融合兩個先進的網路設計理念——具有梯度路徑規劃能力的CSPNet和ELAN——而誕生的。這種設計致力於實作一個既輕量又快速且精確的網路架構,全面最佳化了網路效能和效率。在此基礎上,研究者對ELAN的套用範圍進行了擴充套件,使其不再局限於傳統的摺積層堆疊方式,而是能夠靈活地適配各種計算單元,顯著提升了網路的通用性和適應力。
論文地址:https://arxiv.org/abs/2402.13616
Yolov9原始碼:https://github.com/WongKinYiu/yolov9
系統界面及功能演示
l 系統登入與註冊:包含使用者註冊、建立使用者、重設密碼登功能(預設的使用者名稱為111,密碼也為111)
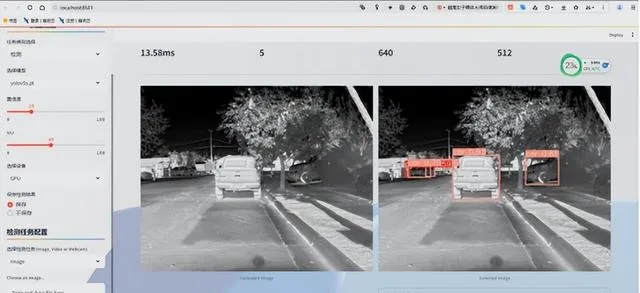
l 登入後系統界面左側可調整:選擇模型、置信度、IoU、選擇裝置、是否保存檢測結果、選擇檢測任務等功能
l 影像檢測:點選Browse files按鈕上傳本地影像(影像和計畫路徑下不要出現中文,為方便測試在計畫的test_images目錄下存放測試圖片,在test_videos目錄下存放測試視訊),在計畫的upload_files目錄會保存使用者上傳的圖片;之後點選開始檢測按鈕系統會自動檢測圖片,並在右側顯示檢測後的結果,在上方顯示測試相關資訊,下方顯示檢測結果,使用者可下載結果(預設下載格式為csv檔),系統會在saved_results保存結果圖片
l 視訊檢測:點選Browse files按鈕上傳本地視訊(影像和計畫路徑下不要出現中文,為方便測試在計畫的test_images目錄下存放測試圖片,在test_videos目錄下存放測試視訊),在計畫的upload_files目錄會保存使用者上傳的視訊;之後點選開始檢測按鈕系統會自動檢測圖片,並在右側顯示檢測後的結果,在上方顯示測試相關資訊,下方顯示檢測結果,使用者可下載結果(預設下載格式為csv檔),系統會在saved_results保存結果視訊
l 網路攝影機檢測:選擇網路攝影機檢測任務後,系統會自動開啟本機網路攝影機並呼叫演算法即時檢測,系統會在saved_results保存結果視訊
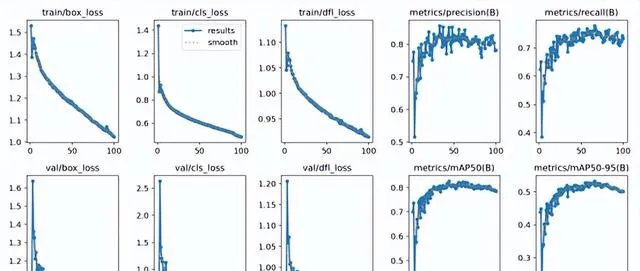
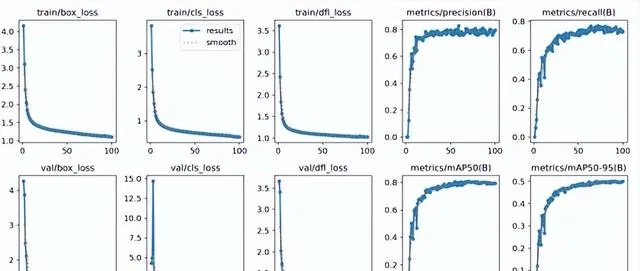
模型訓練及結果
在實驗結果與分析部份,我們使用精度和召回率等指標來評估模型的效能,還透過損失曲線和PR曲線來分析訓練過程。在訓練階段,我們使用了前面介紹的數據集進行訓練,使用了YOLOv8演算法對數據集訓練,總計訓練了100個epochs。從下圖可以看出,隨著訓練次數的增加,模型的訓練損失和驗證損失都逐漸降低,說明模型不斷地學習到更加精準的特征。在訓練結束後,我們使用模型在數據集的驗證集上進行了評估,得到了以下結果。
Ultralytics框架下的YOLOv8m模型的訓練結果
Ultralytics框架下的YOLOv5s模型的訓練結果
Ultralytics框架下的YOLOv6s模型的訓練結果
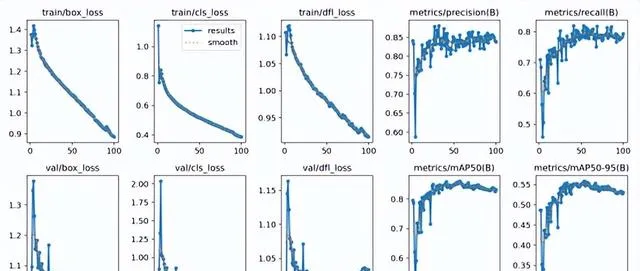
Ultralytics框架下的YOLOv9c模型的訓練結果
綜上,本博文訓練得到的YOLOv8模型在數據集上表現良好,具有較高的檢測精度和魯棒性,可以在實際場景中套用。另外本博主對整個系統進行了詳細測試,最終開發出一版流暢的高精度目標檢測系統界面。另外本博文的PDF與更多的目標檢測辨識系統請關註筆者的微信公眾號 BestSongC
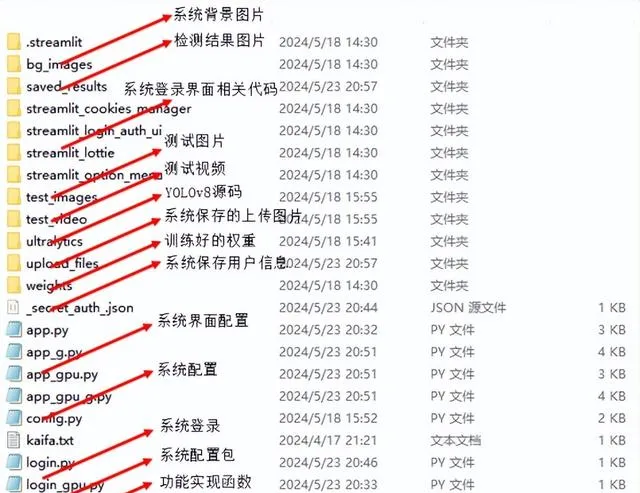
完整計畫目錄如下所示