Happy 投稿
多模態大模型,也有自己的CoT思維鏈了!
廈門大學&騰訊優圖團隊提出 一種名為「領唱員 (Cantor) 」的決策感知多模態思維鏈架構 ,無需額外訓練,效能大幅提升。

在 ScienceQA 上,基於GPT-3.5的Cantor準確率達到了82.39%,相比基於GPT-3.5的思維鏈方法提升了 4.08% 。
在更具挑戰性的MathVista上,基於Gemini的Cantor準確率比原始Gemini提高了 5.9% 。
目前Cantor論文已上傳arXiv,程式碼也已經開源。(地址在文末領取)

思想鏈(Chain-of-Thought, CoT)是一種廣泛套用的提示方法,透過添加中間推理步驟,可以顯著增強大模型的推理能力。
然而,在視覺推理任務中,模型不僅需要把握問題背後的總體邏輯,還需結合影像資訊進行具體分析。
多模態思維鏈應運而生。
現有的多模態思維鏈方法通常將問題分解為多個相關的子任務,並呼叫各種外部工具依次處理。
然而,由於視覺資訊不足和低階感知工具的局限性,這種範式在決策中面臨潛在的「 決策幻覺 」,以及低階感知工具 無法提供高級推理資訊 的挑戰。
Cantor架構賦予多模態大語言模型(MLLM)或大語言模型(LLM)像合唱團中的 領唱員 一樣的協調能力:
首先使MLLM或LLM同時處理視覺和文本上下文,形成 全面的理解並進行決策感知 ,避免決策幻覺。
隨後,將具體任務分配 給MLLM 扮演的「專家」 ,以獲得高級的認知資訊以進一步輔助推理。
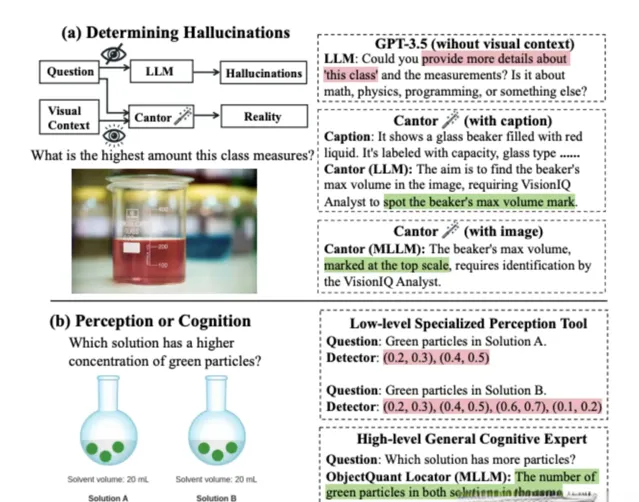
圖中(a)展示了不同視覺資訊對決策的影響:
圖中(b)展示了不同視覺工具的比較:
前者對問題進行分析與解耦,結合各種專家模組特性,生成合理的決策。
後者呼叫各種專家模組執行子任務,並匯總資訊加以思考,生成最終答案。
團隊具體設計了四種專家模組:
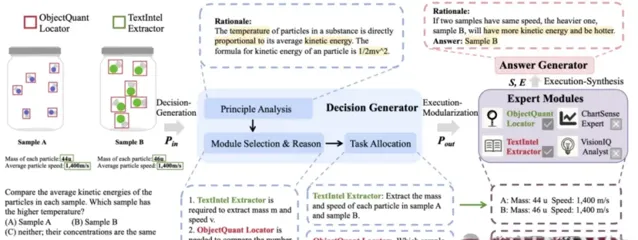
決策生成部份讓MLLM或LLM扮演決策生成器, 也就是充當決策大腦,先對問題進行分析,並結合各專家模組特點,分配子任務,並給出分配理由。
例如要比較兩瓶溶液的溫度大小時,Cantor會先分析粒子溫度與粒子動能的關系,分析粒子動能的運算式為1/2mv^2。並結合影像資訊與專家模組特點,為TextIntel Extractor和ObjectQuant Locator分別分配子任務:
1、提取樣品A和樣品B中每個顆粒的品質和速度。
2、哪個樣品的粒子數量更多?
該步驟有以下特點:
最初,LLM或MLLM被用作決策生成器,充當決策的大腦。
接下來,團隊提供多個專家模組,以完成各種型別的子任務,充當決策的四肢。這種整合確保了決策生成既全面又精細,能夠充分利用了每個模組的優勢。
此後,決策生成器根據從原理分析中獲得的見解,為選定的專家模組量身客製任務,這種動態的任務分配提高了Cantor的效率和效能。
執行又分為模組化執行和匯總執行兩步:
一是模組化執行 :
在這個階段Cantor透過呼叫各種專家模組來完成決策生成階段分配的子任務,以獲得補充資訊。
值得註意的是,團隊只使用MLLM來扮演各種專家模組,以獲得高級的認知資訊輔助推理(如數量的大小關系,位置的相對關系)。
例如,對應上一步分配的子任務,TextIntel Extractor和ObjectQuant Locator分別獲得以下答案:
1、樣品A:品質44u,速度1,400m/s。樣品B:品質46u,速度1,400m/s。
2、兩個樣品的粒子數量相同。
二是匯總執行 :
在這個階段Cantor匯總子任務和子答案的資訊,並結合基本原理,生成最終答案。
其中包括了三個關鍵, 首先 透過提示,讓MLLM或LLM扮演一個知識淵博並且善於整合資訊的答案生成器,這既保證他的專業性,能對問題有基本判斷,又保證他能更好地整合資訊。
其次 為了可解釋性,展示模型的思維過程並提高其思維能力,要求它先生成為答案的基本原理,然後生成相應的選項。
最後 要求Cantor保持理性與批判性,不要完全依賴模組執行獲得的資訊。
Cantor分為兩個版本,Cantor(GPT-3.5)將GPT-3.5作為決策生成器和答案生成器,以及Cantor(Gemini)將Gemini Pro 1.0作為決策生成器和答案生成器。
團隊在ScienceQA和MathVista兩個復雜的視覺推理數據集上進行了實驗。
在ScienceQA上的實驗結果如下:
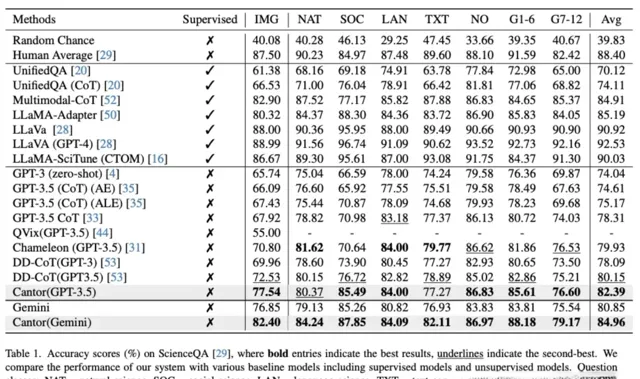
結果顯示使用GPT-3.5作為基本LLM進行決策和回答,Cantor的準確率達到82.39%,比GPT-3.5提示的思想鏈(CoT)提高了4.08%。
使用Gemini作為決策生成器和答案生成器,Cantor的準確率達到84.96%,大大超過了所有免訓練方法,甚至優於UnifiedQA(CoT)和MM-CoT等微調方法。
團隊進一步展示了ScienceQA中IMG類的效能,該類的所有問題都包括了影像上下文。
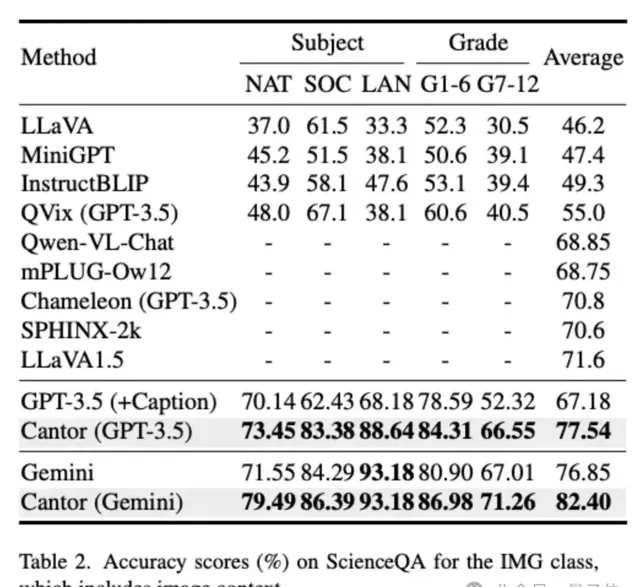
可以看出,基於GPT-3.5的Cantor在各種問題上都顯著超過了基線,甚至超過了一些著名的MLLMs,如SPHINX和LLaVA-1.5。
Cantor(Gemini)效能相比於基線也得到了顯著增長。
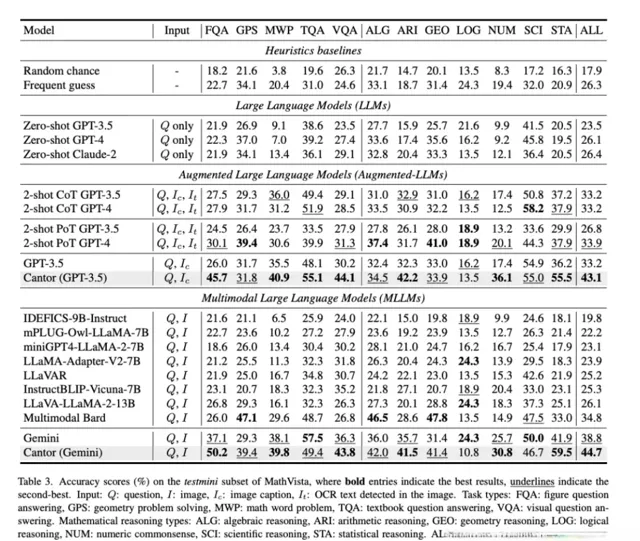
MathVista是一個具有挑戰性的數據集,它將各種數學推理任務與視覺化任務整合在一起。
上表比較了不同方法的效能。從一般的視覺問題回答到專業的數學問題,Cantor在幾乎所有型別的問題中都大大超過了基線。
這表明,正確的決策和模組化專家可以激發他們細粒度、深入的視覺理解和組合推理能力。
值得註意的是,Cantor(GPT-3.5)甚至超過了基於CoT和PoT的GPT-4。
團隊進一步展示了Gemini與Cantor(Gemini)的具體例子比較:
可以看出Cantor透過任務分配,以及讓Gemini進行角色扮演,做到了原來難以做到的事情,並且正確得出了答案。
值得註意的是,即使Gemini在一些問題上答對了,但是它的推理過程其實是有問題的,相比之下Cantor沒有出現這個問題。


論文地址:
https://arxiv.org/abs/2404.16033
計畫地址:
— 完 —











