SignVTCL: Multi-Modal Continuous Sign Language Recognition Enhanced by Visual-Textual Contrastive Learning
标题 : SignVTCL:通过视觉文本对比学习增强的多模态连续手语识别
地址 : https://arxiv.org/pdf/2401.11847.pdf
摘要 : 手语识别(SLR)在促进听力受损社群的交流中发挥着至关重要的作用。SLR是一项弱监督任务,整个视频都用手语词汇进行注释,这使得在视频片段中识别相应的手语词汇变得具有挑战性。最近的研究表明,SLR的主要瓶颈是由于大规模数据集的有限可用性而导致的训练不足。为了解决这一挑战,我们提出了SignVTCL,这是一个通过视觉文本对比学习增强的多模态连续手语识别框架,充分利用了多模态数据和语言模型的泛化能力。SignVTCL同时整合了多模态数据(视频、关键点和光流)来训练统一的视觉骨干,从而产生更强大的视觉表示。此外,SignVTCL包含了一种视觉文本对齐方法,包括词汇级和句子级对齐,以确保在个别手语词汇和句子级别上实现视觉特征和手语词汇的精确对应。在三个数据集(Phoenix-2014、Phoenix-2014T和CSLDaily)上进行的实验证明,与先前方法相比,SignVTCL取得了最先进的结果。
解决的问题 :
该论文要解决的问题是提高手语识别框架的性能,通过结合视觉和文本对比学习,充分利用多模态数据的潜力和语言模型的泛化能力。具体来说,该论文提出了一个名为SignVTCL的框架,该框架能够同时整合视频、关键点和光学流等多种模态数据,训练出一个统一的视觉主干网络,从而产生更稳健的视觉表示。同时,该框架还关注了句子级别的对齐问题,旨在将视觉特征和文本特征在句子级别上进行整合和校准,以便更全面地理解句子中包含的语义和上下文信息。通过这种方式,该框架旨在提高手语识别的准确性和鲁棒性,从而为聋哑人群提供更好的交流和理解服务。
解决的方法 :
该论文解决的方法主要是利用多模态数据,包括视频、文本和关键点序列,来理解和识别手语。
首先,该方法从视频中提取关键点,并将每个提取的关键点视为独立的通道输入到模型中。这些关键点序列可以用作表示手的形状和位置,从而提供有关手语动作的重要信息。
其次,该方法利用光学流来捕捉手语动作的微妙细节,这有助于更准确地识别手语。光学流提供了一种密集的运动表示,使得模型能够更好地理解手语动作。
最后,该方法使用深度网络架构RAFT来提取高质量的光学流信息。RAFT被设计用于提取光学流,可以熟练地从视频数据中获取相关信息。提取的光学流信息被存储为一系列图像,这样就可以将光学流信息表示为类似于视频数据的形式。
为了有效地从这三种模态中学习视觉表示,该方法构建了一个包含三个分支的网络。每个分支由S3D网络的头四个块组成,这是一种常用于视频理解任务的的三维卷积网络架构。在关键点分支中,第一个块的第一个卷积层被替换以适应关键点的输入格式。每个分支将输入数据处理成帧级别的特征f {v,k,o} = {f {v,k,o}}t T/4t=1 ∈ RT/4×dv,然后将这些特征单独馈送到我们头网络中的不同时间头中,其中dv是视觉隐藏维度。
通过这种方法,该论文成功地利用多模态数据来理解和识别手语,从而为手语识别领域的发展做出了贡献。
创新点 :
提出了SignVTCL框架,通过多模态连续的手势语言识别,有效地利用了多模态数据和语言模型的泛化能力。同时,SignVTCL整合了视频、关键点和光学流等多模态数据,训练出一个统一的视觉主干网络,从而产生了更稳健的视觉表示。
在SignVTCL中,论文引入了一种视觉-文本对齐方法,将词级别和句子级别的对齐结合起来,确保了视觉特征与注释之间在单个词和句子层面上的精确对应。此外,为了优化视觉和预训练文本知识的保留,论文还提出了特征适配器,通过冻结预训练的文本编码器并将其用作教师模型来进行监督学习。
系统架构 :
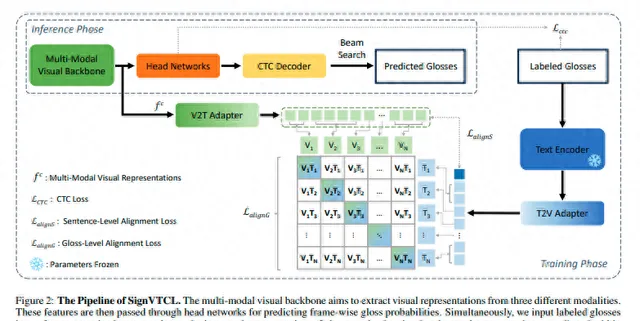
结果 :

结论 :
在这篇论文中,我们提出了SignVTCL,这是一个多模态连续手语识别框架,整合了视频、关键点和光流等多种模态,共同学习视觉表示。通过结合这些模态,SignVTCL捕捉了手语中复杂的手部运动和动态的身体部位运动,增强了模型对手语的理解并提高了识别能力。此外,我们引入了一种视觉文本对齐方法,该方法在词汇和句子两个层面上对齐视觉和文本特征嵌入,从而在视觉符号和文本上下文之间建立了有意义且精确的对应关系,提高了SLR的性能。在多个数据集上进行的广泛实验证明了我们的SignVTCL在取得最先进性能方面的有效性。我们期望所提出的SignVTCL可以激发其他工作探索在视频理解任务中的多模态学习和对比学习。
实际应用价值 :
- 多模态信息融合:论文提出了一种多模态信息融合的方法,通过将视频、关键点、光学流和文本信息进行联合处理,可以更全面地理解视频内容,为视频分析、理解、摘要生成等任务提供了新的思路和方法。
- 跨模态特征对齐:通过使用Video-to-Text和Text-to-Video适配器,该论文实现了视觉和文本特征之间的对齐。这有助于解决诸如视频描述生成、视觉问答等跨模态任务,使得计算机可以更好地理解和处理多模态信息。
- 模型可扩展性:该论文提出的方法可以方便地扩展到更大的数据集和任务中,有助于提高模型的性能和泛化能力。
- 应用场景广泛:该论文提出的方法可以应用于各种场景,如视频摘要、视频描述生成、视觉问答、行为识别等,具有广泛的应用前景。
- 可解释性强:该论文的方法通过使用CTC损失函数和Temporal Linear Layer等结构,使得模型具有较好的可解释性,有助于理解模型的工作原理和改进模型的设计。











