专注LLM深度应用,关注我不迷路
AI Agent如火如荼,在数据分析领域,基于自然语言的交互式数据分析AI智能体为我们勾画了一幅美好的愿景:动动嘴你就可以获得想看的数据、指标与分析图表。但实际上,在业务场景包罗万象、且绝对精确性要求极高的数据分析领域,不管是OpenAI的高级数据分析(原代码解释器,Code Interpreter),还是自行借助开源框架构建Text2SQL/Text2Code等解决方案,在应对较复杂、特别是领域特征明显的分析任务时,都远无法达到企业应用的可用性要求。最近,微软推出了一个新的开源框架 - TaskWeaver: 一款用于无缝规划与执行数据分析任务的、代码优先的Agent框架,能够有效协调各种自定义插件来完成自然语言描述的数据分析任务 。本文将深入TaskWeaver,了解其设计思想、架构并进行实测。
基本思想与架构
【驱动力】
TaskWeaver的诞生来自于在此之前构建基于LLM的数据分析Agent中的一些长期存在的困难: 不管你是借助于LangChain还是类似AutoGen的Agent框架,采用Text2SQL还是Text2Code,对复杂数据分析任务,特别是行业特征明显、领域特定的数据分析任务,当前的解决方案完成性都较差,有很高的不确定性 。这些问题体现在:
* 某个行业做客户分析时要求首先进行特定的异常数据清洗
* 把多个数据源的数据抽取到一起合并后进行汇总、分析与可视化
* 获得特定数据源的数据后,使用者通过对话进行即席查询分析
【TaskWeaver架构】
TaskWeaver的架构并不复杂,我们借用官方文档图来了解其主要组成部分与各个组件之间的关系:
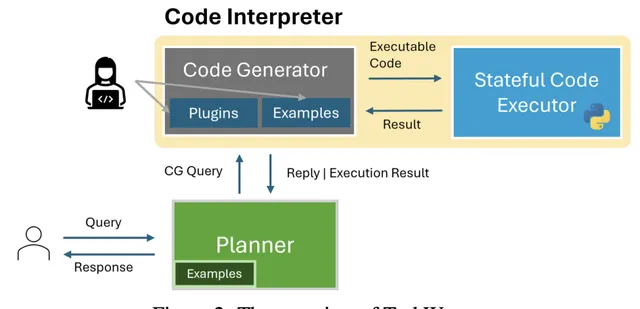
这里对每个组件先做简单介绍:
Planner(规划器) :充当系统的入口点并与用户进行交互。它的职责包括:
Code Generator(代码生成器) :代码生成器为Planner生成给定子任务的Python,生成的代码会充分考虑两个组件的应用:
Code Executor(代码执行器): 代码执行器负责执行代码生成器生成的代码,并在整个会话期间维护代码上下文: 由于一个任务可能会拆分成多个子任务,并与用户产生多次交互,因此也会存在多次执行代码的过程,代码执行器就需要在多次执行代码的过程中维护上下文信息与中间数据状态 。(类似JupyterNotebook中的交互式Python编码)
实例测试与观察
本节用一个实例来深入了解与测试TaskWeaver的任务完成过程。重点考察几个上文提到的重要能力:
为了便于观察,我们采用TaskWeaver官方提供的webUI(一个简单的数据分析Agent)来进行交互。项目内容放在其Project目录即可,包括配置文件、需要使用的插件、Examples等;在对话过程中,日志与其他输出产物也会保存在该目录下。
【数据与准备】
我们仍然用一个保险开支数据来做源数据,准备工作包括:

...from taskweaver.plugin import Plugin, register_plugin@register_plugin class SqlPullData(Plugin):def __call__(self, query: str):...return df, (f"I have generated a SQL query based on `{query}`.\nThe SQL query is {sql}.\n"f"There are {len(df)} rows in the result.\n"f"The first {min(5, len(df))} rows are:\n{df.head(min(5, len(df))).to_markdown()}")
cd playground/UI/
chainlit run app.py
现在我们可以通过Localhost:8000来访问这个简单的数据分析Agent!通过自然语言与其交互,完成指定数据分析任务。
【数据分析任务测试】
我们通过对话输入一个数据分析任务,来观察TaskWeaver的整个任务完成过程,这里的任务输入是:
「从数据库中提取客户保险开支数据,并对比分析不同地区的保险开支情况,制作图表呈现。」
我们来观察Planner(任务规划及用户对话)、CI(代码解释器,包括CG代码生成器、CE代码执行器)之间的协调工作过程。
1. 首先,Planner会将任务拆分成子任务。 值得注意的是,planner在生成子任务计划的过程中,有一个自我优化提炼的过程,会根据任务之间的执行关系(比如是否存在路径依赖),来适当的合并子任务,从初始化计划(Initial plan)生成最终计划(Final plan)。在生成计划后,planner会按照计划步骤来执行计划,首先要求CI代码解释器执行第一个步骤:

2. CI收到Planner的消息,自动生成执行代码(CG)并执行(CE)。这里可以观察到, 由于我们提供了获取数据的插件,所以代码解释器会调用自定义的插件来获取数据 ,并成功执行获得了1338条数据。
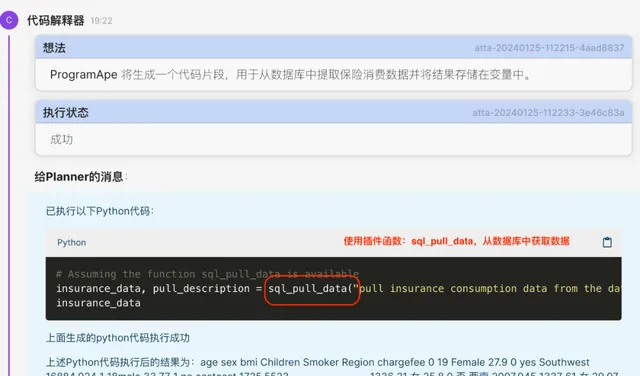
3. 成功获取数据后,Planner要求CI执行计划的下一个步骤。 即进行数据分析并创建图表。当然,在实际应用中,你完全可以定制一个领域内特定的数据清洗的插件,要求在数据分析之前首先完成数据清洗。此处我们直接进行分析。
4. CI接收到Planner的消息后,继续生成代码并执行。 不幸的是,在这一步代码执行中报错了。可以看到这里的错误过程处理: 在收到代码执行(CE)的错误结果后,代码生成器(CG)会尝试自我检查、纠错并重新生成代码 。
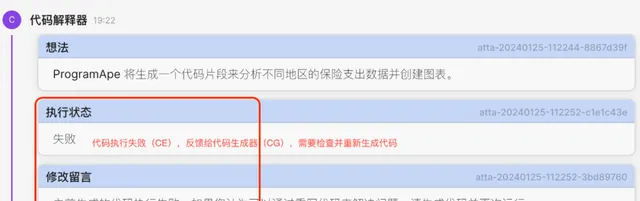
5. CG观察到代码执行的错误消息后,自我思考,并发现了错误所在,然后重新生成了新的代码并执行成功 。并将执行成功的消息反馈给了Planner:
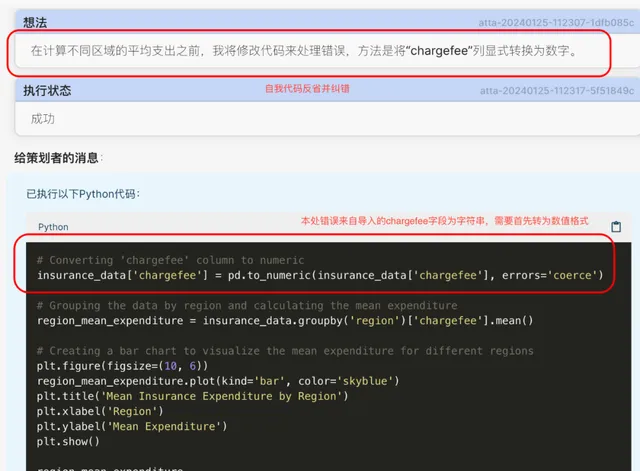
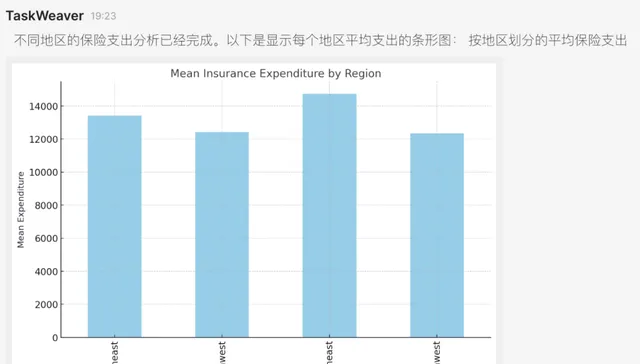
6. Planner在收到成功的消息后,将执行的结果(此处为生成的分析图表)响应给用户:
最后我们将看到如下的输出图表:
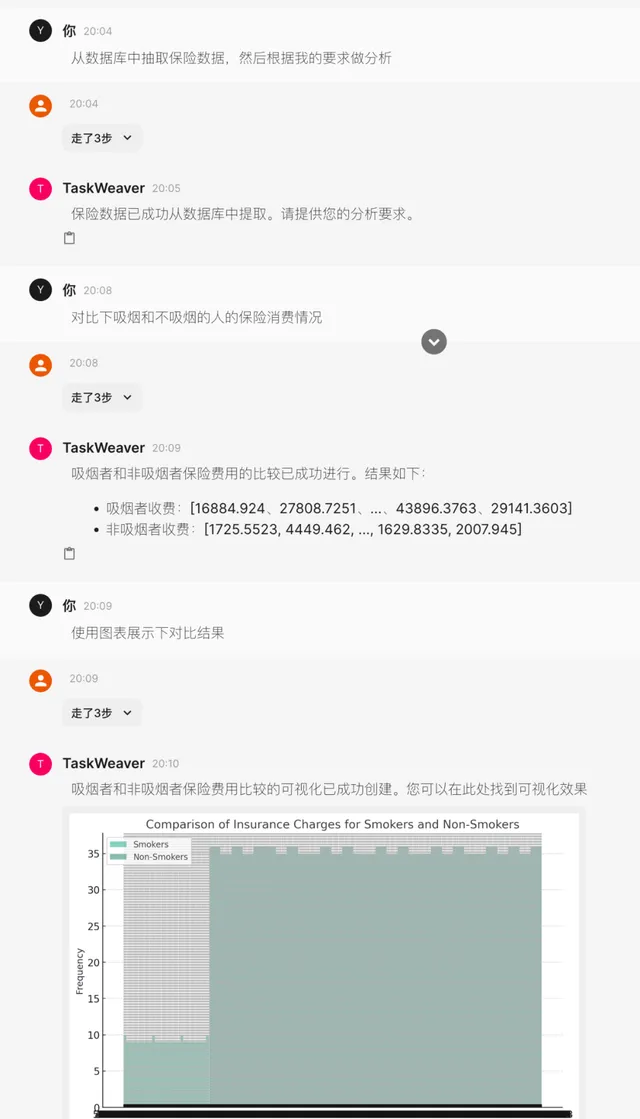
7. 当然,由于TaskWeaver 在一次Session的过程中,多个子任务的代码执行状态及结果会自动在Memory中保存传递 ,无需借助于生成中间文件。因此,这也增加了多轮对话的交互式分析的便捷性。比如, 我们可以用如下的方式来完成一次循序渐进的数据分析任务:
突出特点总结
借助于上面的测试过程,简单地总结TaskWeaver这款微软出品的数据分析Agent框架的一些重要亮点:
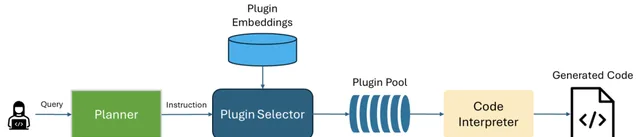
TaskWeaver 具有动态插件选择功能。在收到用户请求后,只有与该请求相关的插件才会从可用插件中被选中,这确保了在处理任务时使用最合适的插件工具,而不会因为插件过多导致Prompt过载等现象。动态插件选择的原理我们在之前的文章中介绍过,即采用对插件说明进行向量化,然后通过请求的语义搜索,来获得最相关的插件列表:
除了这些我们在测试中能够体验到的能力之外,根据官方文档介绍,TaskWeaver还具有 代码安全检查 (防止生成代码的非安全操作)、 LLM上下文压缩 (防止过长的上下文导致的LLM提示溢出)、 支持简单模式 (简单任务不通过planner直接进入CI)、或者 Plugin-only模式 (禁止非Plugin调用的代码)等独特设计,另外还有一些新特性也在Roadmap中进行了规划,我们期待TaskWeaver未来能够在数据分析领域的Agent应用中大放异彩。
END











