大約在一年前,OpenAI的GPT-4重磅釋出,即刻刷爆全網, 「強大」 、 「顛覆」 、 「炸裂」 、 「變革」 、 「改變世界」 、 「未來已來」 幾乎是持續霸屏的關鍵詞。
如今,OpenAI帶著最新的研究成果Sora再度席卷而來。即便已經被GPT-4震撼過,從新聞報道和媒體的敘述中可以看出,Sora的亮相依然艷驚四座,令人拍案叫絕,比之GPT有過之而無不及。
仿佛一夜之間,AI圈已換了天地。此時也更加凸顯出了人類語言是多麽貧瘠且毫無新意,媒體對Sora的評價並沒有跳脫出當初描述DALL-E或ChatGPT的關鍵詞匯。
自Sora面世以來,網上已經掀起了無數討論的熱潮,大致可歸為這樣幾類:
「震驚貼」 :描述Sora的功能有多強大、多炫酷、多顛覆,哪些行業、職業將迎來機遇或面臨挑戰和威脅;
「技術貼」 :分析和討論Sora的技術原理、可能的套用、突破與缺陷;
「爭辯貼」 :這一類的話題最為廣泛,主要包含技術原理、商業化、安全性等的討論。
無論是哪一種討論,其龐大的資訊量都讓人目不暇接,再加上資訊質素良莠不齊,不少人可能會越看越迷惑,因此,本文試圖用更簡單易懂的方式,去厘清圍繞Sora的諸多問題與事件的整體脈絡,盡量從多個視角去了解Sora。
Sora來了,AI圈大變天?
Sora的名字取自日語「天空」的寓意,象征著「無限的創造潛力」,它是OpenAI最新宣布的一款文本到影片的人工智能模型(text-to-video model),也有人將其視為文本轉影片的GPT-3。
盡管OpenAI目前還沒有正式釋出Sora,但這也不妨礙該模型出場就以斷層第一的實績空降C位,僅憑demo影片就「吊打」同行的同類別產品(如Runway-Gen-2、Lumiere、Make-a-Video等),斬獲一片「遙遙領先」的呼聲。

△目前市面上已釋出的文生影片模型
根據OpenAI官網的「技術文件」介紹,Sora能夠根據文本、影像、影片輸入,生成(或合成、向前向後擴充套件)具有不同寬高比和分辨率的高質素、高保真度的1分鐘影片(或高畫質圖片),且生成的影片具有 3D一致性 、 遠端一致性 、 物件永續性 以及 環境互動等功能 。
這些特性換句話說,就是符合真實世界或者說是人類視覺習慣的效果呈現。
△Sora生成的影片demo
在技術原理方面,OpenAI並沒有過多透露,只是大而化之地描述了Sora 是將Diffusion擴散模型 (DALL-E 3) 與transformer架構 (ChatGPT) 相結合。這種混合可以讓模型處理影片(影像幀的時間序列),就像 ChatGPT 處理文本一樣。
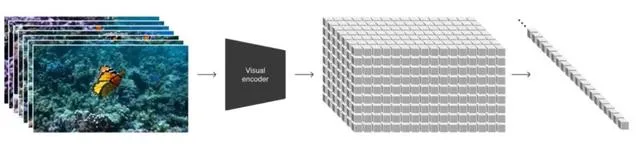
△OpenAI官網文件中Sora技術原理示意圖
有關這項技術的很多內容(如訓練數據等)都處於保密狀態,因此網上有非常多Sora相關技術原理的討論和猜測,但即便是AI專家也會給人一種令人眼花繚亂的感覺。
世界模型:從「激變」到「激辯」
在輿論場上,圍繞Sora的辯論十分激烈,已然形成「百家爭鳴」的局面。支持的、反對的、質疑的、觀望的、蹭熱度的……其中有各行業的專家、技術大牛、相關從業者、商界領袖等等。總結起來不外乎三點:
1)技術的完備性:準確性、因果關系等;
2)技術的安全性:私密問題、倫理問題、版權問題、法律問題等;
3)技術的套用:商業化、行業前景等。
有些內容是AI領域老生常談的,所以這裏講講有趣且值得關註的話題。
Sora是否理解物理世界?世界是一個巨大的模型?
首先是OpenAI給Sora的定位,當中提到了 「世界模擬器」 (world simulator)的概念。OpenAI對此沒有進行更多闡釋,只是籠統地稱其是「作為構建物理世界的影片生成模型」。
然而,這個概念對於理解Sora及其相關討論非常重要,一些主要的爭論也是圍繞其展開。

比如Sora真的懂物理世界嗎?
這個問題的爭議點在於,Sora生成的影片往往讓人眼前一亮,乍一看也接近現實,符合物理世界的規律,但只要仔細觀察就會發現它存在的不合理之處,這些錯誤在OpenAI釋出的demo影片中都能找到。
比如四條腿的螞蟻、反重力的椅子、突然出現和消失的物體、詭異的構造和運動方式、玻璃杯奇怪的碎裂方式等。
△demo影片中的「翻車」現象
這些缺陷明顯都與OpenAI引以為傲的時空連續性和物體永續性不符,不免讓人懷疑,Sora是真的理解物理世界,還是僅僅在關聯和拼湊像素?
對於Sora作為「世界模擬器」的說法,圖靈獎得主,Meta首席AI科學家Yann LeCun是最矚目的公開反駁者,他直言「透過生成像素來模擬世界的行為,註定失敗」。

長期活躍在AI領域的紐約大學心理學和神經科學名譽教授Gary Marcus也表達了類似的觀點。
他以Sora生成影片中的錯誤為例,對OpenAI所謂的物件永續性提出了質疑,並表示「Sora不是一個叠代的、基於定律的物理引擎,而是一個粗暴的野獸」。
輝達高級研究科學家Jim Fan對此進行了補充,提出了兩個解釋的角度:

(1)該模型可能根本沒有學習並掌握物理知識,只是在拼湊像素;
(2)模型實作了一個內部物理引擎,但這個引擎還不夠好,就像虛幻引擎 v1,在流體和可變形等方面的物理模擬要比v5差很多,渲染也要差得多,而且不符合物理規律。
與之相反的另一派,則是 將Sora這類新成果等同於通用人工智能(Artificial General Intelligence,AGI),或是將其視為實作AGI的一大捷徑 。
360創始人周鴻祎第一時間發了長文談對Sora的看法,他認為Sora離通用人工智能(Artificial General Intelligence,AGI)不遠了,甚至大膽預測這不是10年20年的問題,可能一兩年就能實作。

△周鴻祎發文部份截圖
LeCun和周鴻祎的觀點可以說是眾多討論中最主流的兩類觀點。我其實更偏向於LeCun的思路,周鴻祎說的這些也許是因為他不理解技術底層。
要明白「世界模擬器」是什麽,得先了解AGI中 「世界模型」 (world model)這個關鍵概念。
「世界模型」是對現實或一個可能世界的圖解表達,旨在增進人們對世界的理解和/或做出預測。
構建「世界模型」,就是在整體和細節上對世界進行建模或模擬、對映或復制,包括其性質和組成部份、結構和功能、狀態和行為,涵蓋所有層面和規模。
一般來說,「世界模型」是對整個現實的抽象表示。具體來說,它是對我們世界的空間或時間維度的抽象表示。
「世界模型」是任何智能系統及其知識和學習、推理和行為以及與任何環境互動的關鍵。
人類使用「世界模型」作為大腦中的模擬器。該模型是透過環境中的互動從大量感覺運動數據中學習而獲得的。

△圖源:論文【Deep learning, reinforcement learning, and world models】
「世界模型」有雙重作用:(1) 估計感知未提供的有關世界狀況的缺失資訊,(2) 預測世界未來可能的狀況。
「世界模型」可以預測世界的自然演化,或預測由行為模組提出的一系列動作所導致的未來世界狀態。
「世界模型」是與當前任務相關的那部份世界的模擬器。由於世界充滿不確定性,模型必須能夠表示多種可能的預測。
通常情況下,智能體都會預測它希望世界變成什麽樣,然後采取行動以使該預測成為現實。在此過程中,智能體不斷努力預測和理解周圍環境,生成「世界模型」,以盡量減少目標或信念與環境(感官)證據之間的差異。

△自主智能模型架構,圖源:論文【Deep learning, reinforcement learning, and world models】
空間、時間和因果關系對於任何嚴肅的「世界模型」來說都是核心。
如果一個系統連物件的永續性都無法處理,是否應該將其稱為「世界模擬器」?
而因果關系的錯亂既是Sora的致命硬傷,也是Sora影片中存在各種荒謬錯誤的元兇。
簡而言之,這是由於模型采用了計算概率分布的方法來對影像進行關聯和拼接。問題就出在這裏,僅憑處理自然語言文本上下文之間的連線概率,根本無法推匯出全域的因果關系,整體的合理性就遺失了。
所以,概率統計的相關性並不能精確表達物理規律的因果性,這也是電腦與經濟學最基本的區別。
在經濟學領域,對因果推斷的研究非常重視且由來已久。2021年諾貝爾經濟學獎的其中一半,就是頒給了「對因果關系分析的方法學」作出貢獻的Joshua D.Angrist和Guido W.Imbens。
這裏需要特別指出的是,在Imbens的研究中,他尤其註意將大數據時代的機器學習等新方法吸收到因果推斷的框架當中來,幫助改進因果推斷的質素。同時,越來越多的經濟學學者也正在將因果關系與機器學習相結合,用以檢驗長期以來在經濟學界存在爭議的問題。
從這個角度看,Sora今後的發展可能會需要用到經濟學的這些理論和知識。
如果不能掌握因果關系,AI就不會很聰明。畢竟這是連人類都會遇到的麻煩,就連訓練有素的科學家也容易將相關性誤解為因果關系,或者反之。所以哪怕在合理的情況下,對於因果關系的指出也應該慎重。
就目前所見,Sora做的還是預測影像如何變化,而不是實體在現實中如何變化,這種推理路徑並不是實作AGI所需的物理推理邏輯。
更直白一點說,Sora的技術突破並沒有太大(語言大模型+影像大模型),但工程量超大,也就是用超強算力和超量數據去堆疊效果,基本上是一種以量取勝的思路。

△從左至右,影片的質素隨著訓練計算的增加而提高
這種方法的弊端也是顯而易見的。首先,資源的消耗是巨大的,其次,對數據質素的要求是極高的。
這樣一來,Sora領先同類模型的謎底其實早就寫在了謎面上。
所謂的降維打擊,一定程度上是數據、算力、自有模型等優勢的加持,這也是目前手握三大模型(文+圖+影片)的OpenAI超強的技術壁壘。
科技博主Gabor Cselle在其他模型上輸入了Sora的起始幀,透過偵錯prompts和參數,使其輸出與Sora相似的內容。結論是:Sora僅在較長的場景中表現更好。

△Gabor的測試影片
Sora透過影像的聯想和預測生成的影片或許偽造了一種真實感,但所有的故障都表明了這種偽造的局限性。這也是「Sora理解物理世界」的說法受到質疑的原因之一,因為它太容易被證偽了。

△生成式AI的構建模組
△大語言模型的種類
Sora展現出來的局限性,也是目前生成式AI模型的通病,類似於大語言模型產生的「幻覺」,可以改善,但很難根除。
縱然Sora有其強大可取之處,可是和ChatGPT一樣,它們的底層都沒有真正的理解能力。所以,Sora的成功可以看作是一場創新與規模的勝利,但將它等同於AGI未免過於樂觀了些。
當AGI被反復提及,成為一種時髦的標簽甚至淪為行銷炒作的流量密碼,各行業將其奉為萬能靈藥,然而大多數時候都是只看廣告不管療效。
既然是對最新科研成果的討論,至少應該遵循基本的科學態度。
對一些底層概念和邏輯的理解,有助於更加客觀理性地辨析Sora在AI發展中所處的階段和層級,明白其突破意味著什麽,也能看清它的不足與挑戰。
狂歡之下,誰是贏家?
到目前為止,OpenAI已經創造了兩個「奇跡」,且不論它們實際對世界改變了多少,從影響力的角度看,在生成式AI軍備競賽全面開啟之後,OpenAI 已經以高調的姿態贏了兩次,但它並不是唯一的受益者。

△AI芯片版圖
在AI產業變革的浪潮中,資本永遠是嗅覺最靈敏的,業界的風吹草動都會反映在市場股價的走勢上。
Sora聲名大噪,幾家歡喜幾家愁,借著OpenAI掀起的這陣東風,有的乘風而起,有的隨風下落。
凡是與AI相關的主題或概念,都有不同程度的上漲,而OpenAI的競爭對手以及可能被AI威脅的產業,則成為Sora的第一批受害者。

在Sora釋出後的24小時內,AI相關的虛擬貨幣平均上漲了7.7%,其中,OpenAI的CEO山姆·柯曼(Sam Altman)創立的世界幣Worldcoin(WLD)漲幅最大,為30%。
AI的「神話」與「祛魅」
英國科幻小說家Arthur C. Clarke曾說:「足夠先進的技術與魔法沒有什麽區別」。
Sora的出現無異於對世界施展了一次魔法,同時帶動了科技、資本、行銷、媒體等諸多領域的狂歡,制造了一個又一個奇觀,但與ChatGPT釋出時社交媒體的盛況相比,總給人一種昨日重現的錯覺。
△實際上,ChatGPT在全球範圍內的熱度整體更高,而Sora釋出後在國內熱度更高
由於OpenAI一如既往地對Sora的大部份資訊守口如瓶,有關Sora的爭論也持續發酵並且愈演愈烈。
我在之前的一篇推播中也講過(【頂流成名靠什麽?】),利用或是刻意營造事物的「神秘感」,是行銷炒作的一種手段。
「神秘感」加上「稀缺」的黃金組合,讓Sora的刷屏傳播變得無往不利,這時再追問OpenAI是否有意為之其實沒有太大意義,因為效果顯然已經足夠好了。
說到保密,其實不只是OpenAI被戲稱為「CloseAI」,保密在矽谷並不是什麽新鮮事,理由大概都是防止商業競爭或其技術危險擴散,或兩者兼有。
史丹福大學基礎模型研究中心曾推出一項指數,用來衡量OpenAI、谷歌和Anthropic等10家科技巨頭對人工智能的保密程度,下面是對它們透明度評級的結果。
大約十年前,科技和法律學者Frank Pasquale創造了「黑匣子社會」這個詞,用來指科技平台為了鞏固其在人們生活中的主導地位,因而變得越來越不透明。雖然人們對AI可能會產生的隱患存在種種擔憂,但黑匣子已經成為常態,許多人也早已習慣了它的存在。
於是,在這一領域中,令人毛骨悚然的驚嘆或是奇怪的半知半解是常見的現象。
自AI誕生以來,人們對它的想象往往是烏托邦或反烏托邦式的。面臨強大而未知的事物,除了有種令人眩暈的力量感之外,或許還有一種屈辱的幻滅感。畢竟,這是人類使用過的最先進的技術。
AI領域資訊不透明,在一定程度上神化了它。新事物出現或是尚未被人類理解之前,都屬於神秘領域,某種意義上就是神話。
面對神話敘事,人們要麽膜拜要麽恐懼,但這兩種態度對於認識AI和推動其發展都無助益。正如市場中的過度狂熱會產生泡沫,過度恐慌也會引發危機。對於Sora這類最新的研究成果,最好的應對方式就是既不過於神話也不輕易低估。
破除神話敘事和消除恐懼感的關鍵,在於打破或是減少資訊差。
資訊時代的大數據並沒有幫助我們減少資訊差,而生成式AI技術的發展,正在創造一個"影子被誤認為是真實事物的世界"。在其助推之下,假訊息和垃圾資訊可能更加猖獗泛濫,進而加劇資訊差的產生。也許未來,資訊差會導致一種新型的貧富差異。
然而,在可見的將來,AI還會繼續發展。在某些方面,人類已經被AI打敗,未來將會怎樣,沒人能給出答案。
可以肯定的是,眼見為實早已成為歷史。人類的認知方式也將隨著AI的前進演化潛移默化地發生改變。
就拿ChatGPT和Sora來說,如果過去是先相信,再核查,今後就是先核查,再相信。
△兩年內,文生圖模型的進展
有網友調侃道:以後的普通人是不是只能吃著預制菜,讀著ChatGPT生成的假新聞,看著AI寫的劇本Sora生成的影視劇,戴著VR眼鏡環遊外太空,過上一種高科技低成本的賽博龐克生活,而真實自然的體驗反而是最昂貴。
最後,借用麥克盧漢的幾段話作為本文的結尾。
以未來主義和擬古主義為手段去迎戰急劇變革,常常是徒勞無益的。指向昔日的馬車時代也好,指向未來的抗重力運載工具也好,都不足以回答汽車的挑戰。不過,這兩種相同的向前看和向後看的方式,是避免眼前的經驗中斷而常用的方法。
鑒於人們面對挑戰時有無窮無盡的力量使自己陷入無知無覺的催眠狀態,我們可以認為,意誌力在維護生存中與智力一樣重要。今天,我們要做到資訊靈通、見多識廣,同樣是需要意誌力的。
當一個時代的技術向一個方向迅猛突進時,智慧完全可以召喚一種與之抗衡的反沖擊。











