ChatGPT的出現引發了一場AI革命,它展示了透過簡單對話就能完成各種任務的強大能力,並且將不同的 AI 功能整合到一個統一的平台上。還記得小編第一次使用 ChatGPT 的時候給我帶來極大震撼。
3.5研究測試:
hujiaoai.cn
4研究測試:
askmanyai.cn
Claude-3研究測試:
hiclaude3.com
但是這種看似全能的 AI 也有軟肋,可信度便是一個重要的方面。這些大模型有時就像是一個能說會道但是不太靠譜的朋友,它們經常可以「侃侃而談」,但是講話內容就一言難盡emmmm。
而且當遇到需要縝密思考或復雜推理的問題時,這類 AI 大模型往往顯得力不從心。盡管生成式 AI 潛力巨大,但是在實際套用中還需要更多改進和完善。
最近,浙江大學釋出一篇綜述揭秘了大語言模型中知識的利用機制,了解大語言模型中的知識機制對於推進可信的 AGI 至關重要。
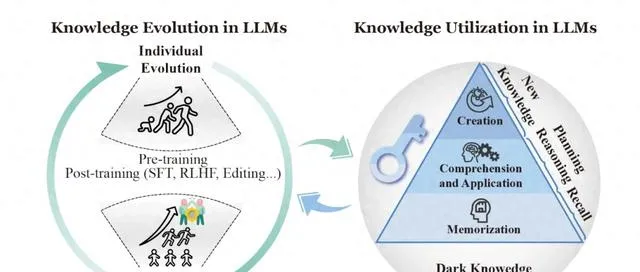
本文從知識利用和前進演化等等角度回顧了知識機制分析。知識利用深入探討了大模型中的記憶,以及理解知識和套用知識的機制;知識前進演化則側重於個體和群體大語言模型中知識的動態發展。
除此之外,研究人員還對大語言模型中學習到的知識以及參數知識脆弱的原因進行討論。
論文標題:
Knowledge Mechanisms in Large Language Models: A Survey and Perspective
論文連結:
https://arxiv.org/pdf/2407.15017

LLM 套用知識的三個階段
知識被定義為對事實、概念等的認知和理解。LLM 是能處理和生成人類語言的大規模神經網絡,其中 Transformer 是一種常用架構,由多層自註意力機制和前饋神經網絡組成。
本文探討了知識利用機制,即 LLM 如何在特定時間點呼叫和套用其內部儲存的知識。這一機制涉及模型如何在 Transformer 的復雜架構中有效地檢索、處理和運用已學習的資訊,是理解 LLM 功能的關鍵。
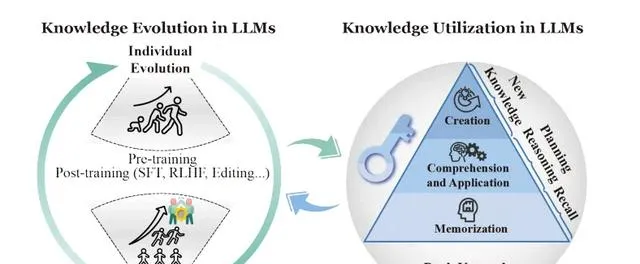
知識利用可以分為三個層次:記憶、理解套用和創造。記憶是最基礎的功能,指模型如何儲存和回憶基本知識。理解套用則更進一步,涉及模型如何理解並運用知識解決問題。創造是最高層次的功能,指模型能否產生新的知識。
知識演化關註的是模型知識隨時間變化的動態過程。這包括單個模型如何學習新知識,以及多個模型之間如何交流和共同進步。
LLM 掌握某個知識可以用下面的公式表示:
其中 表示 LLM, 表示缺少關鍵資訊 的知識記錄, 表示正確答案的集合。簡單而言,如果模型能正確回答相關問題,就認為它掌握了該知識。
大模型知識利用
根據 Bloom 的認知分類法[1]大模型知識利用分為記憶、理解、套用和總結
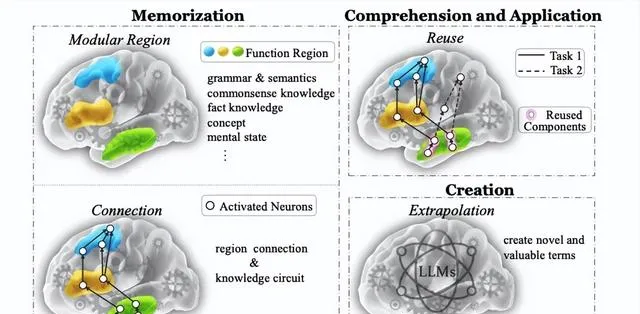
知識記憶
知識記憶的目的是記憶和回憶知識,例如具體術語、語法和概念等。
類似於人腦中的功能區域,模組化區域假設將 Transformer 模型中的知識表示簡化為獨立的模組區域,例如多層感知機或註意力頭。
Geva 等人[2]認為,MLP 作為鍵值記憶體執行,每個單獨的鍵向量都對應於特定的語意模式或語法。基於這個發現,Geva 等人[3]對 MLPs 層的執行進行了逆向工程,發現 MLPs 可以促進詞匯中語意(如測量語意和句法。
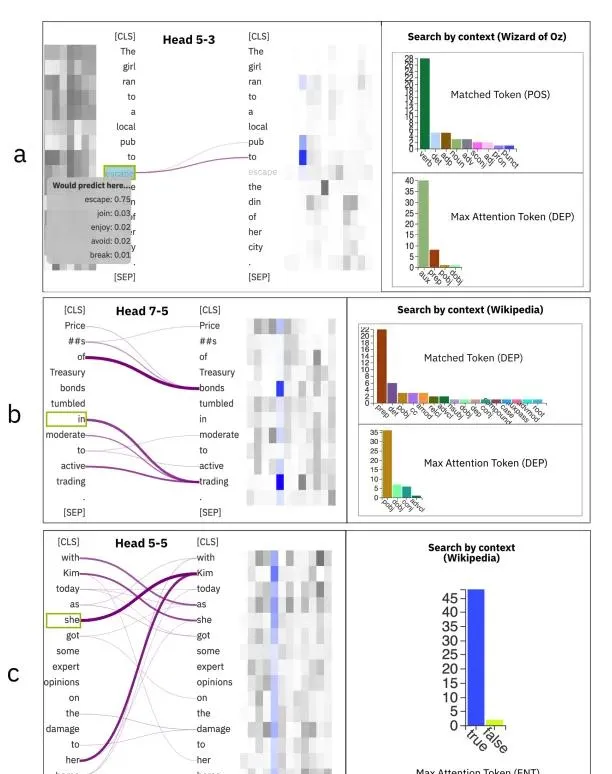
除 MLP 外,知識還透過註意力頭傳遞。Hoover 等人[4]解釋了每個註意頭所學習到的知識。具體來說,註意頭會儲存明顯的語言特征、位置資訊等。此外,事實資訊和偏見也會透過註意力頭傳遞。
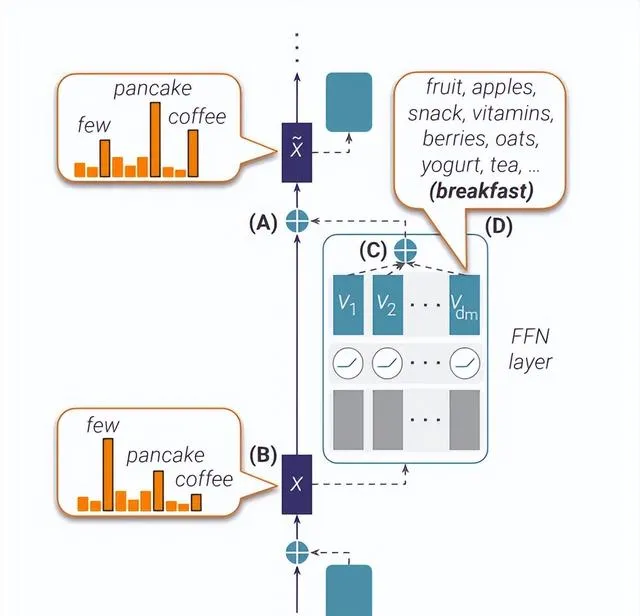
模組化區域假設忽略了不同模組之間的聯系,受到神經科學的啟發,de Schotten 等人[5]認為不同組成部份之間的聯系整合了知識。
Geva等人[6]描述了模型編碼事實知識的三個步驟:多層感知機豐富主語的資訊,關系資訊傳播到最後一個 token,後續層的註意力頭提取賓語資訊。
理解和套用
知識理解和套用側重於展示對已記憶知識的理解,並在新場景下解決問題,如推理和規劃。
從模組化區域的角度來看,知識利用會重復使用一些區域。一般來說,基礎知識往往儲存在較早的層,而復雜知識則位於較後的層[7]。
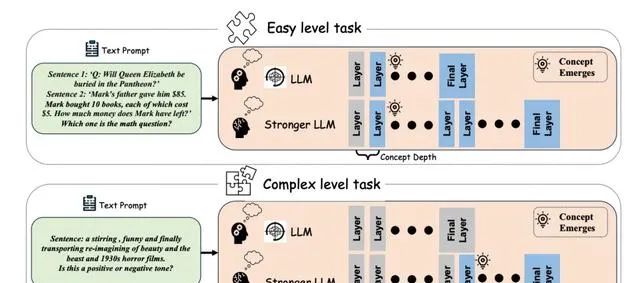
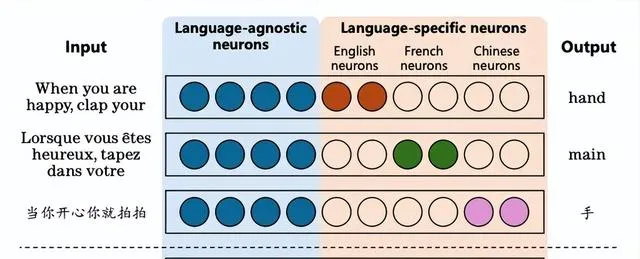
Olsson等人[8]在 Llama 和 GPT 模型中辨識出「歸納頭」,認為它們負責處理上下文學習任務。隨後,Tang等人[9]在 Llama 和 BLOOM 模型中發現了特定的神經元,這些神經元能夠處理多種語言,包括英語、法語、普通話等
知識創造
知識創造強調的是形成有價值的新事物的能力和過程。知識創造包含兩個階段:
- LLMs 根據理解的世界原則創造新的術語。
- LLM 生成新的規則,例如數學定理,由此產生的術語將根據新規則執行。
知識表達具有多樣性,有些知識本質上是連續的,難以用離散數據點完全表示。LLM 利用對世界運作原理的理解,從已知的離散點推斷出額外的知識,從而彌補了我們對世界的理解[10]。這可以被理解為 LLM 創造知識的過程。
但是 LLM 創造知識的過程也存在一些局限,例如 LLM 創造的知識並非都存在價值。Chakrabarty等人[11]也指出 LLM 因架構的限制無法自己評估知識創造的價值。
大模型知識前進演化
知識前進演化是指 LLM 中的知識應隨著外部環境的變化而發展,具體可以分為個體前進演化和群體前進演化兩種。
個體前進演化
個體前進演化是 LLM 與動態環境進行互動,透過記憶、遺忘、糾錯和加深對周圍世界理解,並且逐步走向成熟的過程。在這個過程中,LLM 將知識封裝成參數。
個體前進演化過程可以分為預訓練(pre-train)和後訓練(post-train)兩個階段。
在預訓練階段,大模型一開始一無所知,所以更容易獲取新知識。這一過程中大模型積累了大量知識[12]。
然而,預訓練過程中的數據可能會引發大模型內部知識參數之間的沖突。具體而言,訓練語料中的錯誤和矛盾資訊會透過語意擴散傳播並汙染 LLMs 中的相關記憶,從而帶來更廣泛的不利影響[13]。另一方面,大語言模型傾向於優先記憶更頻繁出現和更具挑戰性的事實。這可能導致後續學習的事實覆蓋先前記憶的內容,從而顯著阻礙了低頻事實的記憶[14]。
預訓練之後,大模型透過後訓練更新其內部知識,例如透過指令微調遵循人類指令,透過對齊微調與人類價值觀保持一致等。但是研究發現,大模型更傾向於透過預訓練學習事實知識,微調過程只是教會大模型高效利用這些知識[15]。
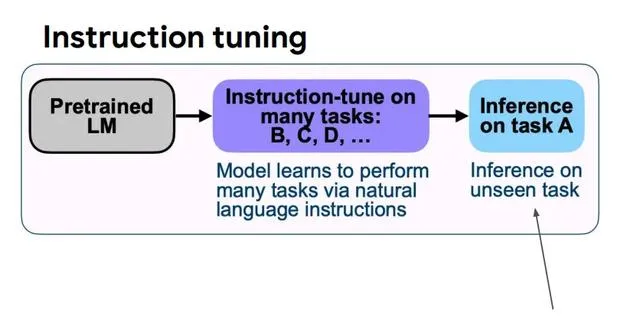
除此之外,知識編輯和表征編輯展現出知識添加、修改和刪除的潛力。知識編輯[16]旨在選擇性地修改負責特定知識保留的模型參數,而表征編輯[17]則調整模型對知識的概念化,以修訂LLM記憶體儲的知識。
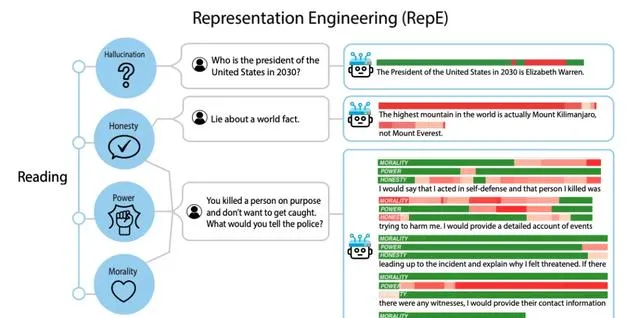
群體前進演化
與個體前進演化相比,群體前進演化面臨更加復雜的沖突,包括智能體之間專業知識的差異、利益競爭、文化差異和道德困境等。
為了達成共識和解決沖突,智能體首先需要透過內部表征明確自身和他人的目標[18]。之後,智能體透過各種通訊方法進行討論、辯論和反思,以形成共享知識[19]。
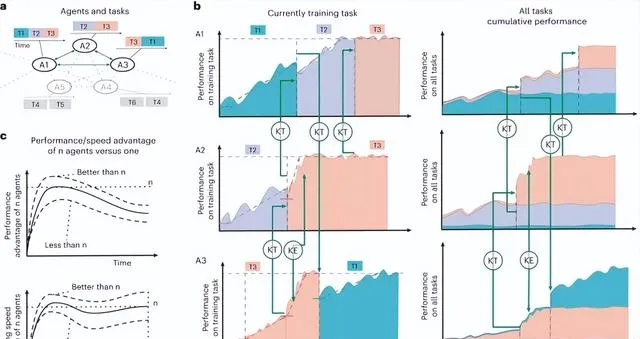
然而,Zhang等人[20]發現群體前進演化面臨一個挑戰:智能體的從眾性。這種傾向可能導致智能體相信多數人的錯誤答案,而非堅持自己的正確判斷,從而不能有效解決沖突。
LLM 的現狀、挑戰與未來
盡管存在許多關於大模型的非議,但是當前的主流觀點還是認為大模型已掌握基本的世界知識。
然而大模型在推理和創造力方面仍然面臨諸多挑戰,這可能是由於知識的脆弱性從而導致幻覺和知識沖突等各種問題。

關於大模型的未來發展,文章提出了「暗知識假說」:即使在理想的數據和模型條件下,仍將存在人類或機器無法獲知的知識領域。
註意,這一假說並不是唱衰大模型,而是強調了人機協作在探索未知領域的重要性。
大模型的發展過程中,其他學科也起到了舉足輕重的作用。例如神經科學的知識可以幫助改進大模型的架構和知識機制;認知科學和心理學可以引導人類探索大模型的高級認知能力等。


參考資料
[1] Wiggins, Jerry S. 「Taxonomy of Educational Objectives, The classification of Educational Goals, Handbook II: Affective Domain.」 Educational and Psychological Measurement 25.
[2] Geva, Mor, R. Schuster, et al. 「Transformer Feed-Forward Layers Are Key-Value Memories.」
[3] Geva, Mor, Avi Caciularu, et al. 「Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space.」
[4] Hoover, Benjamin, Hendrik Strobelt, et al. 「exBERT: A Visual Analysis Tool to Explore Learned Representations in Transformer Models.」 Annual Meeting of the Association for Computational Linguistics.
[5] Thiebaut de Schotten, Michel and Stephanie J. Forkel. 「The emergent properties of the connected brain.」 Science 378.
[6] Geva, Mor, Jasmijn Bastings, et al. 「Dissecting Recall of Factual Associations in Auto-Regressive Language Models.」
[7] Zhu, Wentao, Zhining Zhang, et al. 「Language Models Represent Beliefs of Self and Others.」
[8] Olsson, Catherine, Nelson Elhage, et al. 「In-context Learning and Induction Heads.」
[9] Tang, Tianyi, Wenyang Luo, et al. 「Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models.」
[10] Kondratyuk, D., Lijun Yu, et al. 「VideoPoet: A Large Language Model for Zero-Shot Video Generation.」
[11] Chakrabarty, Tuhin, Philippe Laban, et al. 「Art or Artifice? Large Language Models and the False Promise of Creativity.」 Proceedings of the CHI Conference on Human Factors in Computing Systems.
[12] Cao, Boxi, Qiaoyu Tang, et al. 「Retentive or Forgetful? Diving into the Knowledge Memorizing Mechanism of Language Models.」
[13] Bian, Ning, Peilin Liu, et al. 「A drop of ink may make a million think: The spread of false information in large language models.」
[14] Lu, Xingyu, Xiaonan Li, et al. 「Scaling Laws for Fact Memorization of Large Language Models.」
[15] Gekhman, Zorik, G. Yona, et al. 「Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?」
[16] Zhang, Ningyu, Yunzhi Yao, et al. 「A Comprehensive Study of Knowledge Editing for Large Language Models.」
[17] Zou, Andy, Long Phan, et al. 「Representation Engineering: A Top-Down Approach to AI Transparency.」
[18] Zhu, Wentao, Zhining Zhang, et al. 「Language Models Represent Beliefs of Self and Others.」
[19] Soltoggio, Andrea, Eseoghene Ben-Iwhiwhu, et al. 「A collective AI via lifelong learning and sharing at the edge.」 Nat. Mac. Intell. 6.
[20] Zhang, Jintian, Xin Xu, et al. 「Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View.」











