專註LLM深度套用,關註我不迷路
AI Agent如火如荼,在數據分析領域,基於自然語言的互動式數據分析AI智能體為我們勾畫了一幅美好的願景:動動嘴你就可以獲得想看的數據、指標與分析圖表。但實際上,在業務場景包羅萬象、且絕對精確性要求極高的數據分析領域,不管是OpenAI的高級數據分析(原程式碼直譯器,Code Interpreter),還是自行借助開源框架構建Text2SQL/Text2Code等解決方案,在應對較復雜、特別是領域特征明顯的分析任務時,都遠無法達到企業套用的可用性要求。最近,微軟推出了一個新的開源框架 - TaskWeaver: 一款用於無縫規劃與執行數據分析任務的、程式碼優先的Agent框架,能夠有效協調各種自訂外掛程式來完成自然語言描述的數據分析任務 。本文將深入TaskWeaver,了解其設計思想、架構並進行實測。
基本思想與架構
【驅動力】
TaskWeaver的誕生來自於在此之前構建基於LLM的數據分析Agent中的一些長期存在的困難: 不管你是借助於LangChain還是類似AutoGen的Agent框架,采用Text2SQL還是Text2Code,對復雜數據分析任務,特別是行業特征明顯、領域特定的數據分析任務,當前的解決方案完成性都較差,有很高的不確定性 。這些問題體現在:
* 某個行業做客戶分析時要求首先進行特定的異常數據清洗
* 把多個資料來源的數據抽取到一起合並後進行匯總、分析與視覺化
* 獲得特定資料來源的數據後,使用者透過對話進行即席查詢分析
【TaskWeaver架構】
TaskWeaver的架構並不復雜,我們借用官方文件圖來了解其主要組成部份與各個元件之間的關系:
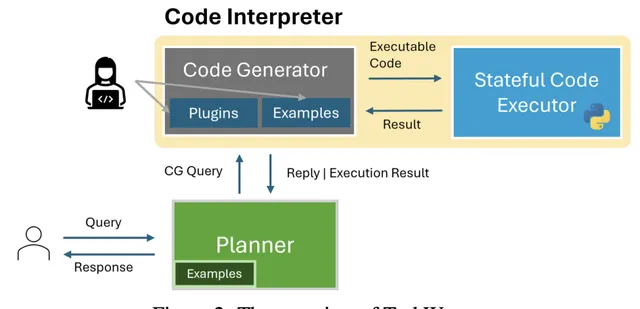
這裏對每個元件先做簡單介紹:
Planner(規劃器) :充當系統的入口點並與使用者進行互動。它的職責包括:
Code Generator(程式碼生成器) :程式碼生成器為Planner生成給定子任務的Python,生成的程式碼會充分考慮兩個元件的套用:
Code Executor(程式碼執行器): 程式碼執行器負責執行程式碼生成器生成的程式碼,並在整個會話期間維護程式碼上下文: 由於一個任務可能會拆分成多個子任務,並與使用者產生多次互動,因此也會存在多次執行程式碼的過程,程式碼執行器就需要在多次執行程式碼的過程中維護上下文資訊與中間數據狀態 。(類似JupyterNotebook中的互動式Python編碼)
例項測試與觀察
本節用一個例項來深入了解與測試TaskWeaver的任務完成過程。重點考察幾個上文提到的重要能力:
為了便於觀察,我們采用TaskWeaver官方提供的webUI(一個簡單的數據分析Agent)來進行互動。專案內容放在其Project目錄即可,包括配置檔、需要使用的外掛程式、Examples等;在對話過程中,日誌與其他輸出產物也會保存在該目錄下。
【數據與準備】
我們仍然用一個保險開支數據來做源數據,準備工作包括:

...from taskweaver.plugin import Plugin, register_plugin@register_plugin class SqlPullData(Plugin):def __call__(self, query: str):...return df, (f"I have generated a SQL query based on `{query}`.\nThe SQL query is {sql}.\n"f"There are {len(df)} rows in the result.\n"f"The first {min(5, len(df))} rows are:\n{df.head(min(5, len(df))).to_markdown()}")
cd playground/UI/
chainlit run app.py
現在我們可以透過Localhost:8000來存取這個簡單的數據分析Agent!透過自然語言與其互動,完成指定數據分析任務。
【數據分析任務測試】
我們透過對話輸入一個數據分析任務,來觀察TaskWeaver的整個任務完成過程,這裏的任務輸入是:
「從數據庫中提取客戶保險開支數據,並對比分析不同地區的保險開支情況,制作圖表呈現。」
我們來觀察Planner(任務規劃及使用者對話)、CI(程式碼直譯器,包括CG程式碼生成器、CE程式碼執行器)之間的協調工作過程。
1. 首先,Planner會將任務拆分成子任務。 值得註意的是,planner在生成子任務計劃的過程中,有一個自我最佳化提煉的過程,會根據任務之間的執行關系(比如是否存在路徑依賴),來適當的合並子任務,從初始化計劃(Initial plan)生成最終計劃(Final plan)。在生成計劃後,planner會按照計劃步驟來執行計劃,首先要求CI程式碼直譯器執行第一個步驟:

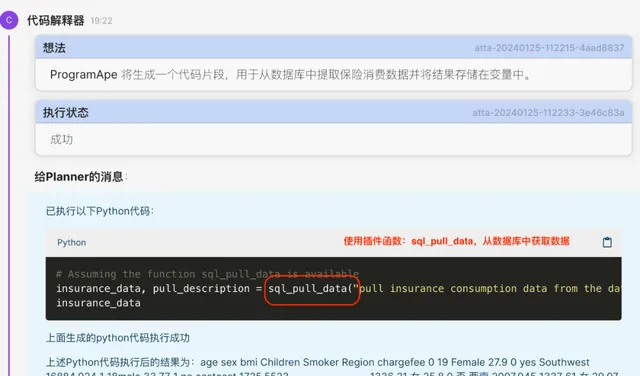
2. CI收到Planner的訊息,自動生成執行程式碼(CG)並執行(CE)。這裏可以觀察到, 由於我們提供了獲取數據的外掛程式,所以程式碼直譯器會呼叫自訂的外掛程式來獲取數據 ,並成功執行獲得了1338條數據。
3. 成功獲取數據後,Planner要求CI執行計劃的下一個步驟。 即進行數據分析並建立圖表。當然,在實際套用中,你完全可以客製一個領域內特定的數據清洗的外掛程式,要求在數據分析之前首先完成數據清洗。此處我們直接進行分析。
4. CI接收到Planner的訊息後,繼續生成程式碼並執行。 不幸的是,在這一步程式碼執行中報錯了。可以看到這裏的錯誤過程處理: 在收到程式碼執行(CE)的錯誤結果後,程式碼生成器(CG)會嘗試自我檢查、糾錯並重新生成程式碼 。
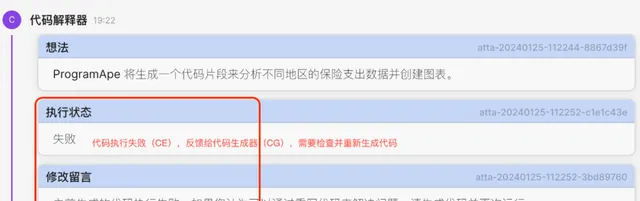
5. CG觀察到程式碼執行的錯誤訊息後,自我思考,並行現了錯誤所在,然後重新生成了新的程式碼並執行成功 。並將執行成功的訊息反饋給了Planner:
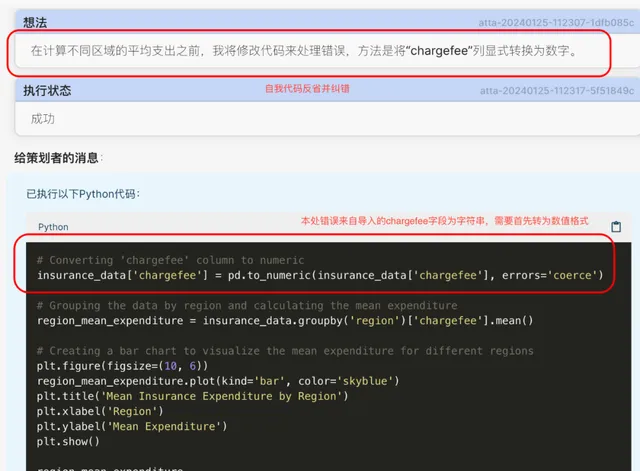
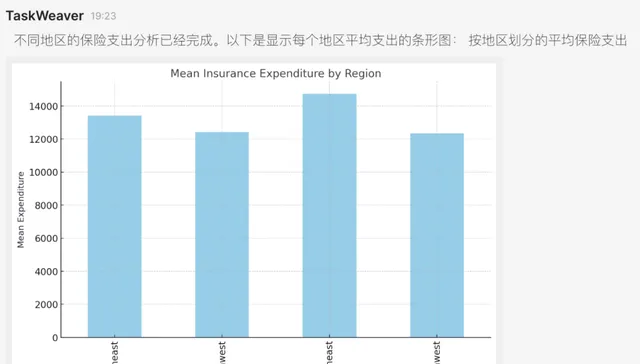
6. Planner在收到成功的訊息後,將執行的結果(此處為生成的分析圖表)響應給使用者:
最後我們將看到如下的輸出圖表:
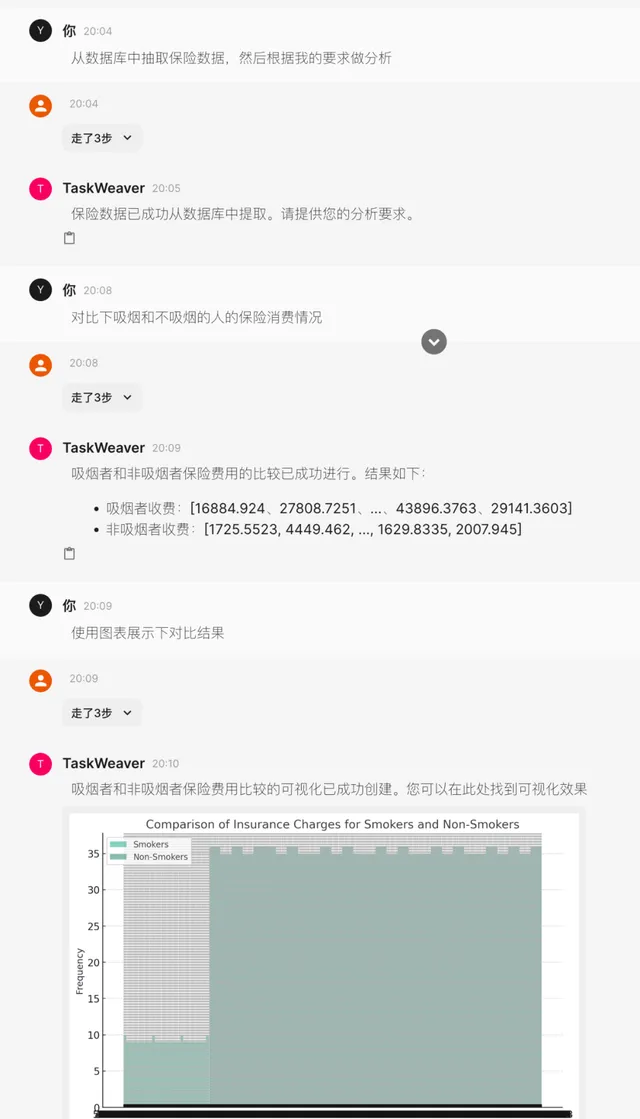
7. 當然,由於TaskWeaver 在一次Session的過程中,多個子任務的程式碼執行狀態及結果會自動在Memory中保存傳遞 ,無需借助於生成中間檔。因此,這也增加了多輪對話的互動式分析的便捷性。比如, 我們可以用如下的方式來完成一次循序漸進的數據分析任務:
突出特點總結
借助於上面的測試過程,簡單地總結TaskWeaver這款微軟出品的數據分析Agent框架的一些重要亮點:
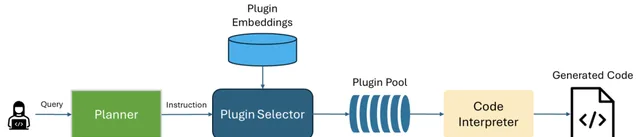
TaskWeaver 具有動態外掛程式選擇功能。在收到使用者請求後,只有與該請求相關的外掛程式才會從可用外掛程式中被選中,這確保了在處理任務時使用最合適的外掛程式工具,而不會因為外掛程式過多導致Prompt過載等現象。動態外掛程式選擇的原理我們在之前的文章中介紹過,即采用對外掛程式說明進行向量化,然後透過請求的語意搜尋,來獲得最相關的外掛程式列表:
除了這些我們在測試中能夠體驗到的能力之外,根據官方文件介紹,TaskWeaver還具有 程式碼安全檢查 (防止生成程式碼的非安全操作)、 LLM上下文壓縮 (防止過長的上下文導致的LLM提示溢位)、 支持簡單模式 (簡單任務不透過planner直接進入CI)、或者 Plugin-only模式 (禁止非Plugin呼叫的程式碼)等獨特設計,另外還有一些新特性也在Roadmap中進行了規劃,我們期待TaskWeaver未來能夠在數據分析領域的Agent套用中大放異彩。
END











