最近多模态生成领域也在「神仙打架」,比如Meta的全新训练方法Transfusion,用单个模型就能同时生成文本和图像!
还有之前华为、清华提出的个性化多模态内容生成技术PMG,生成的内容可「量身定制」,更能满足偏好。
这些效果炸裂的新成果证明了 多模态生成一直是研究热门 ,更实际点的证明还有:
因此多模态生成依旧是我们非常好的选择,想抓紧投中顶会给自己加码的同学可以考虑。这里为了帮助各位快速了解这个方向目前的最新动态,我整理好了 10篇 多模态生成今年最新的论文 给各位作参考,代码基本都有。
论文原文+开源代码需要的同学关注「学姐带你玩AI」公众号,那边回复「多模态生成」获取。
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
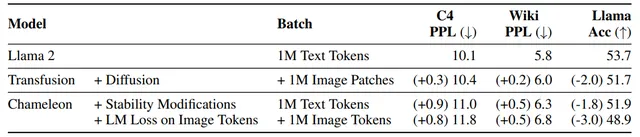
方法: 论文一个多模态模型训练的配方Transfusion,可以处理离散数据(如文本或代码)和连续数据(例如图像、音频和视频数据)。Transfusion结合了语言建模损失函数(下一个词预测)和扩散模型,通过单一的transformer来训练混合模态序列,使其能够无缝地生成离散和连续的模态,例如同时生成文本和图像。
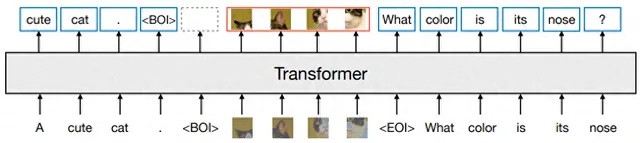
创新点:
PMG: Personalized Multimodal Generation with Large Language Models
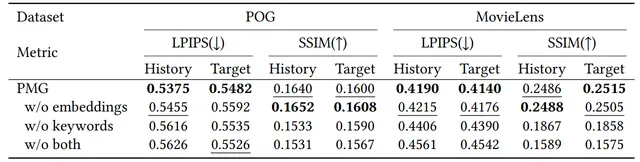
方法: 论文提出了一种基于大语言模型(LLMs)的个性化多模态生成方法(PMG),首先将用户行为转化为自然语言,以便LLM能够理解并提取用户的偏好。然后,将用户偏好输入生成器(如多模态LLM或扩散模型)以生成个性化内容。
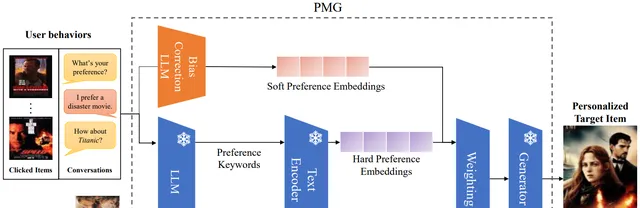
创新点:
ANOLE: An Open, Autoregressive, Native Large Multimodal Models for Interleaved Image-Text Generation
方法: ANOLE是一个开源的多模态模型,专注于交错图像-文本生成。它基于Meta AI的Chameleon模型,通过高效微调少量参数来增强图像和多模态生成能力,而无需依赖扩散模型。
创新点:
Generative Multimodal Models are In-Context Learners
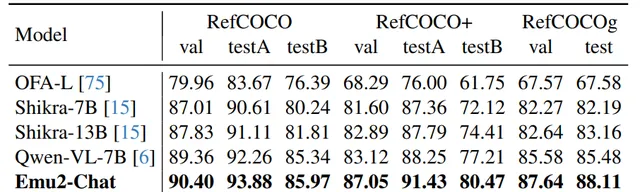
方法: 论文介绍了一个名为 Emu2 的大型多模态生成模型,它通过大规模多模态序列的训练,具备了强大的多模态上下文学习能力。Emu2 能够处理包括文本、图像-文本对和交错的图像-文本-视频等在内的多种数据类型,并且在少量样本或简单指令的情况下解决多模态任务。

创新点:
论文原文+开源代码需要的同学关注「学姐带你玩AI」公众号,那边回复「多模态生成」获取。











