ChatGPT的出现引发了一场AI革命,它展示了通过简单对话就能完成各种任务的强大能力,并且将不同的 AI 功能整合到一个统一的平台上。还记得小编第一次使用 ChatGPT 的时候给我带来极大震撼。
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
但是这种看似全能的 AI 也有软肋,可信度便是一个重要的方面。这些大模型有时就像是一个能说会道但是不太靠谱的朋友,它们经常可以「侃侃而谈」,但是讲话内容就一言难尽emmmm。
而且当遇到需要缜密思考或复杂推理的问题时,这类 AI 大模型往往显得力不从心。尽管生成式 AI 潜力巨大,但是在实际应用中还需要更多改进和完善。
最近,浙江大学发布一篇综述揭秘了大语言模型中知识的利用机制,了解大语言模型中的知识机制对于推进可信的 AGI 至关重要。
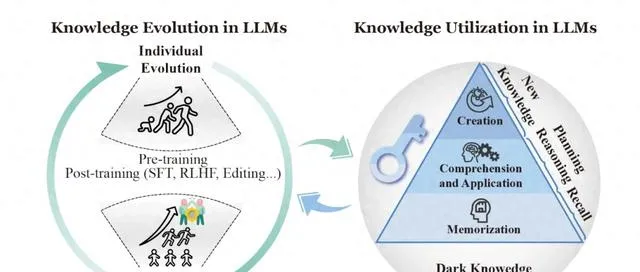
本文从知识利用和进化等等角度回顾了知识机制分析。知识利用深入探讨了大模型中的记忆,以及理解知识和应用知识的机制;知识进化则侧重于个体和群体大语言模型中知识的动态发展。
除此之外,研究人员还对大语言模型中学习到的知识以及参数知识脆弱的原因进行讨论。
论文标题:
Knowledge Mechanisms in Large Language Models: A Survey and Perspective
论文链接:
https://arxiv.org/pdf/2407.15017

LLM 应用知识的三个阶段
知识被定义为对事实、概念等的认知和理解。LLM 是能处理和生成人类语言的大规模神经网络,其中 Transformer 是一种常用架构,由多层自注意力机制和前馈神经网络组成。
本文探讨了知识利用机制,即 LLM 如何在特定时间点调用和应用其内部存储的知识。这一机制涉及模型如何在 Transformer 的复杂架构中有效地检索、处理和运用已学习的信息,是理解 LLM 功能的关键。
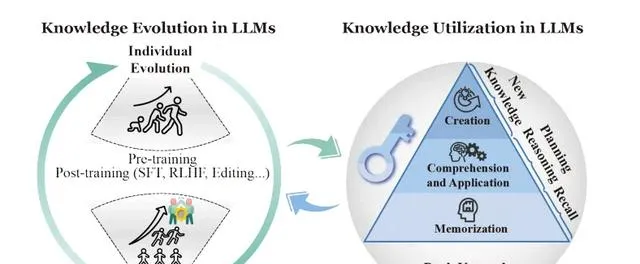
知识利用可以分为三个层次:记忆、理解应用和创造。记忆是最基础的功能,指模型如何存储和回忆基本知识。理解应用则更进一步,涉及模型如何理解并运用知识解决问题。创造是最高层次的功能,指模型能否产生新的知识。
知识演化关注的是模型知识随时间变化的动态过程。这包括单个模型如何学习新知识,以及多个模型之间如何交流和共同进步。
LLM 掌握某个知识可以用下面的公式表示:
其中 表示 LLM, 表示缺少关键信息 的知识记录, 表示正确答案的集合。简单而言,如果模型能正确回答相关问题,就认为它掌握了该知识。
大模型知识利用
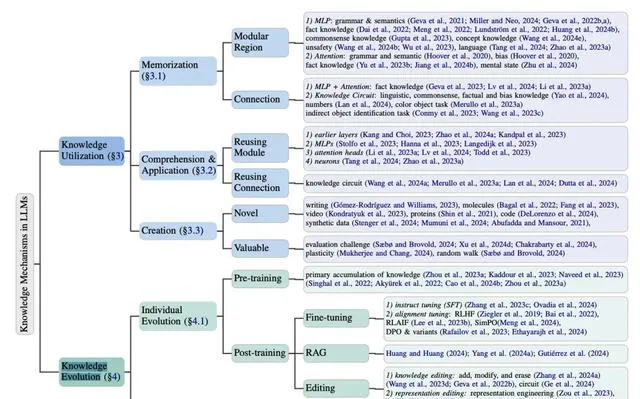
根据 Bloom 的认知分类法[1]大模型知识利用分为记忆、理解、应用和总结
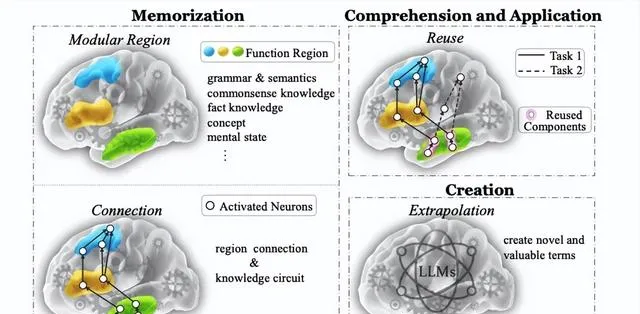
知识记忆
知识记忆的目的是记忆和回忆知识,例如具体术语、语法和概念等。
类似于人脑中的功能区域,模块化区域假设将 Transformer 模型中的知识表示简化为独立的模块区域,例如多层感知机或注意力头。
Geva 等人[2]认为,MLP 作为键值存储器运行,每个单独的键向量都对应于特定的语义模式或语法。基于这个发现,Geva 等人[3]对 MLPs 层的运行进行了逆向工程,发现 MLPs 可以促进词汇中语义(如测量语义和句法。
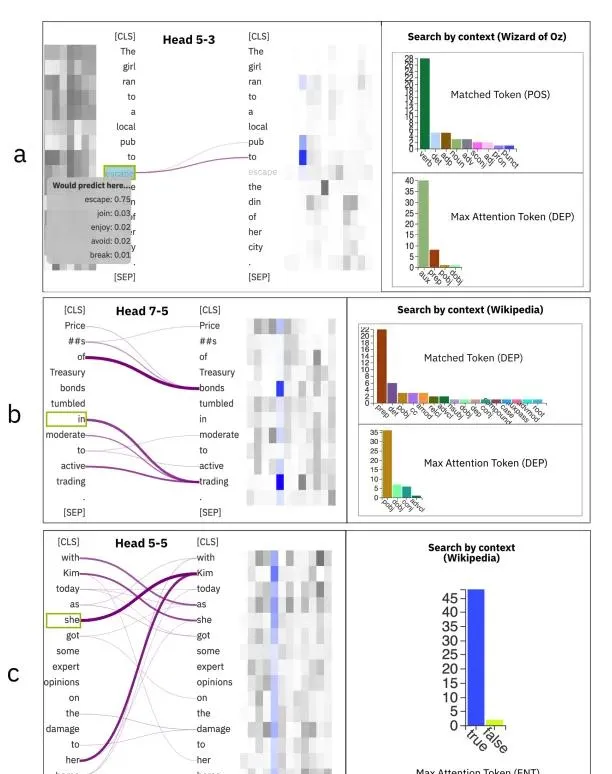
除 MLP 外,知识还通过注意力头传递。Hoover 等人[4]解释了每个注意头所学习到的知识。具体来说,注意头会存储明显的语言特征、位置信息等。此外,事实信息和偏见也会通过注意力头传递。
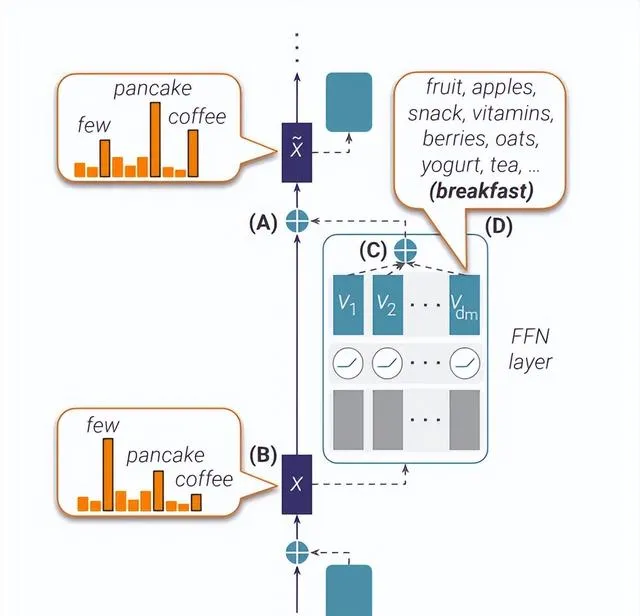
模块化区域假设忽略了不同模块之间的联系,受到神经科学的启发,de Schotten 等人[5]认为不同组成部分之间的联系整合了知识。
Geva等人[6]描述了模型编码事实知识的三个步骤:多层感知机丰富主语的信息,关系信息传播到最后一个 token,后续层的注意力头提取宾语信息。
理解和应用
知识理解和应用侧重于展示对已记忆知识的理解,并在新场景下解决问题,如推理和规划。
从模块化区域的角度来看,知识利用会重复使用一些区域。一般来说,基础知识往往存储在较早的层,而复杂知识则位于较后的层[7]。
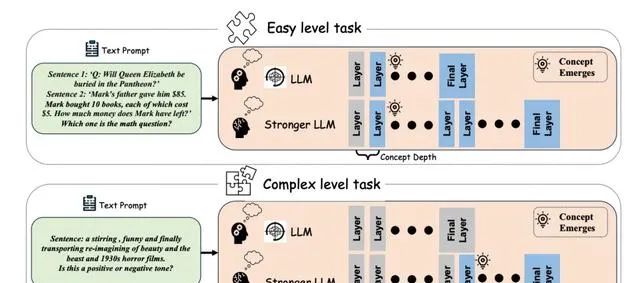
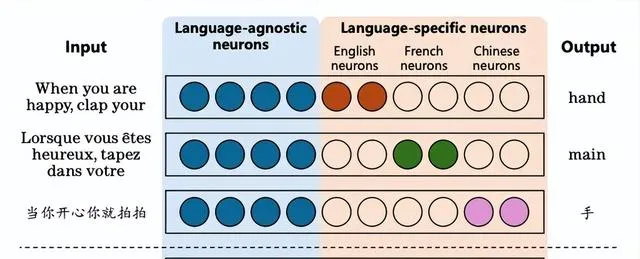
Olsson等人[8]在 Llama 和 GPT 模型中识别出「归纳头」,认为它们负责处理上下文学习任务。随后,Tang等人[9]在 Llama 和 BLOOM 模型中发现了特定的神经元,这些神经元能够处理多种语言,包括英语、法语、普通话等
知识创造
知识创造强调的是形成有价值的新事物的能力和过程。知识创造包含两个阶段:
- LLMs 根据理解的世界原则创造新的术语。
- LLM 生成新的规则,例如数学定理,由此产生的术语将根据新规则运行。
知识表达具有多样性,有些知识本质上是连续的,难以用离散数据点完全表示。LLM 利用对世界运作原理的理解,从已知的离散点推断出额外的知识,从而弥补了我们对世界的理解[10]。这可以被理解为 LLM 创造知识的过程。
但是 LLM 创造知识的过程也存在一些局限,例如 LLM 创造的知识并非都存在价值。Chakrabarty等人[11]也指出 LLM 因架构的限制无法自己评估知识创造的价值。
大模型知识进化
知识进化是指 LLM 中的知识应随着外部环境的变化而发展,具体可以分为个体进化和群体进化两种。
个体进化
个体进化是 LLM 与动态环境进行交互,通过记忆、遗忘、纠错和加深对周围世界理解,并且逐步走向成熟的过程。在这个过程中,LLM 将知识封装成参数。
个体进化过程可以分为预训练(pre-train)和后训练(post-train)两个阶段。
在预训练阶段,大模型一开始一无所知,所以更容易获取新知识。这一过程中大模型积累了大量知识[12]。
然而,预训练过程中的数据可能会引发大模型内部知识参数之间的冲突。具体而言,训练语料中的错误和矛盾信息会通过语义扩散传播并污染 LLMs 中的相关记忆,从而带来更广泛的不利影响[13]。另一方面,大语言模型倾向于优先记忆更频繁出现和更具挑战性的事实。这可能导致后续学习的事实覆盖先前记忆的内容,从而显著阻碍了低频事实的记忆[14]。
预训练之后,大模型通过后训练更新其内部知识,例如通过指令微调遵循人类指令,通过对齐微调与人类价值观保持一致等。但是研究发现,大模型更倾向于通过预训练学习事实知识,微调过程只是教会大模型高效利用这些知识[15]。
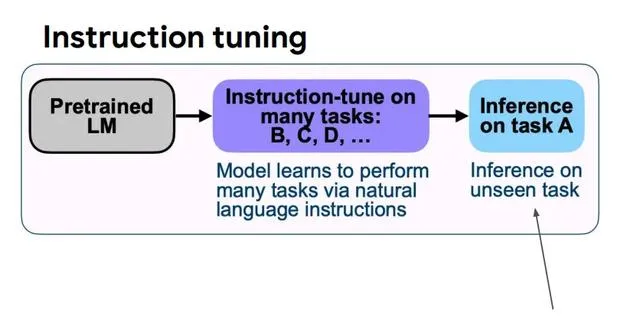
除此之外,知识编辑和表征编辑展现出知识添加、修改和删除的潜力。知识编辑[16]旨在选择性地修改负责特定知识保留的模型参数,而表征编辑[17]则调整模型对知识的概念化,以修订LLM内存储的知识。
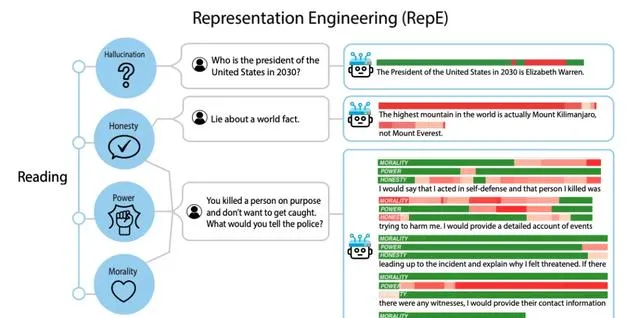
群体进化
与个体进化相比,群体进化面临更加复杂的冲突,包括智能体之间专业知识的差异、利益竞争、文化差异和道德困境等。
为了达成共识和解决冲突,智能体首先需要通过内部表征明确自身和他人的目标[18]。之后,智能体通过各种通信方法进行讨论、辩论和反思,以形成共享知识[19]。
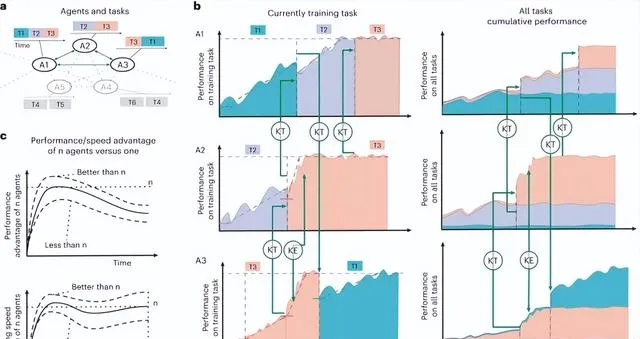
然而,Zhang等人[20]发现群体进化面临一个挑战:智能体的从众性。这种倾向可能导致智能体相信多数人的错误答案,而非坚持自己的正确判断,从而不能有效解决冲突。
LLM 的现状、挑战与未来
尽管存在许多关于大模型的非议,但是当前的主流观点还是认为大模型已掌握基本的世界知识。
然而大模型在推理和创造力方面仍然面临诸多挑战,这可能是由于知识的脆弱性从而导致幻觉和知识冲突等各种问题。

关于大模型的未来发展,文章提出了「暗知识假说」:即使在理想的数据和模型条件下,仍将存在人类或机器无法获知的知识领域。
注意,这一假说并不是唱衰大模型,而是强调了人机协作在探索未知领域的重要性。
大模型的发展过程中,其他学科也起到了举足轻重的作用。例如神经科学的知识可以帮助改进大模型的架构和知识机制;认知科学和心理学可以引导人类探索大模型的高级认知能力等。


参考资料
[1] Wiggins, Jerry S. 「Taxonomy of Educational Objectives, The classification of Educational Goals, Handbook II: Affective Domain.」 Educational and Psychological Measurement 25.
[2] Geva, Mor, R. Schuster, et al. 「Transformer Feed-Forward Layers Are Key-Value Memories.」
[3] Geva, Mor, Avi Caciularu, et al. 「Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space.」
[4] Hoover, Benjamin, Hendrik Strobelt, et al. 「exBERT: A Visual Analysis Tool to Explore Learned Representations in Transformer Models.」 Annual Meeting of the Association for Computational Linguistics.
[5] Thiebaut de Schotten, Michel and Stephanie J. Forkel. 「The emergent properties of the connected brain.」 Science 378.
[6] Geva, Mor, Jasmijn Bastings, et al. 「Dissecting Recall of Factual Associations in Auto-Regressive Language Models.」
[7] Zhu, Wentao, Zhining Zhang, et al. 「Language Models Represent Beliefs of Self and Others.」
[8] Olsson, Catherine, Nelson Elhage, et al. 「In-context Learning and Induction Heads.」
[9] Tang, Tianyi, Wenyang Luo, et al. 「Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models.」
[10] Kondratyuk, D., Lijun Yu, et al. 「VideoPoet: A Large Language Model for Zero-Shot Video Generation.」
[11] Chakrabarty, Tuhin, Philippe Laban, et al. 「Art or Artifice? Large Language Models and the False Promise of Creativity.」 Proceedings of the CHI Conference on Human Factors in Computing Systems.
[12] Cao, Boxi, Qiaoyu Tang, et al. 「Retentive or Forgetful? Diving into the Knowledge Memorizing Mechanism of Language Models.」
[13] Bian, Ning, Peilin Liu, et al. 「A drop of ink may make a million think: The spread of false information in large language models.」
[14] Lu, Xingyu, Xiaonan Li, et al. 「Scaling Laws for Fact Memorization of Large Language Models.」
[15] Gekhman, Zorik, G. Yona, et al. 「Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?」
[16] Zhang, Ningyu, Yunzhi Yao, et al. 「A Comprehensive Study of Knowledge Editing for Large Language Models.」
[17] Zou, Andy, Long Phan, et al. 「Representation Engineering: A Top-Down Approach to AI Transparency.」
[18] Zhu, Wentao, Zhining Zhang, et al. 「Language Models Represent Beliefs of Self and Others.」
[19] Soltoggio, Andrea, Eseoghene Ben-Iwhiwhu, et al. 「A collective AI via lifelong learning and sharing at the edge.」 Nat. Mac. Intell. 6.
[20] Zhang, Jintian, Xin Xu, et al. 「Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View.」











