
在這篇文章中,我們要一起打造一個生成式 AI 新聞搜尋後台。我們的選擇是 Meta 的 Llama-3 8B 模型,這一切都將透過 Groq 的 LPU 來實作。
關於 Groq
如果你還不知道 Groq,那就讓我來介紹一下。Groq 正在重新定義大型語言模型(LLM)中文本生成的推理速度標準。它提供了一種名為 LPU(語言處理單元)的介面引擎,這是一種全新的端到端處理單元系統,為那些包含序列元件的計算密集型套用提供了前所未有的快速推理能力,正如在大型語言模型中看到的那樣。
我們這裏不打算深入討論為什麽 Groq 的推理速度能遠超 GPU。我們的目標是利用 Groq 提供的速度優勢和 Llama 3 在文本生成方面的能力,建立一個與 Bing AI 搜尋、Google AI 搜尋或 PPLX 類似的生成式 AI 新聞搜尋服務。
為什麽是 Llama 3?
Meta 最近釋出的 Llama 3 模型非常受歡迎。其中更大的 70B Llama 3 模型目前在 LMSys LLM 排行榜中位居第五。在英語任務方面,這一模型排名第二,僅次於 GPT-4。
Meta 在其釋出部落格中提到,8B 模型在其類別中表現最佳,而 70B 模型則勝過了 Gemini Pro 1.5 和 Claude 3 Sonnet。
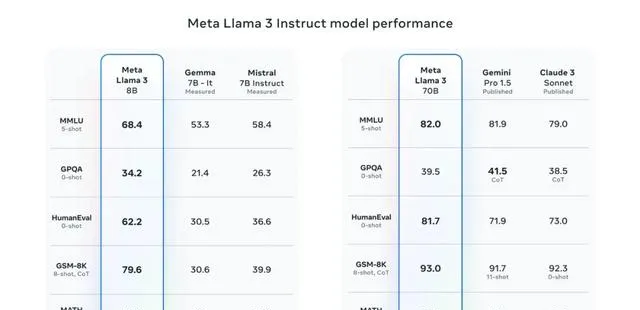
為了展現模型對現實世界情境和問題的理解能力,Meta 建立了一個高品質的人類評估集。這個評估集包括 1800 個情景,覆蓋了 12 個關鍵用例,如尋求建議、頭腦風暴、分類、回答封閉問題、編程、創意寫作、提取資訊、扮演角色、回答開放問題、推理、覆寫和總結。
這個數據集被模型開發團隊保密,以避免模型在這些數據上過度擬合。在測試中,Llama 3 70B 在與 Claude Sonnet、Mistral Medium、GPT-3.5 和 Llama 2 的比較中表現出色。
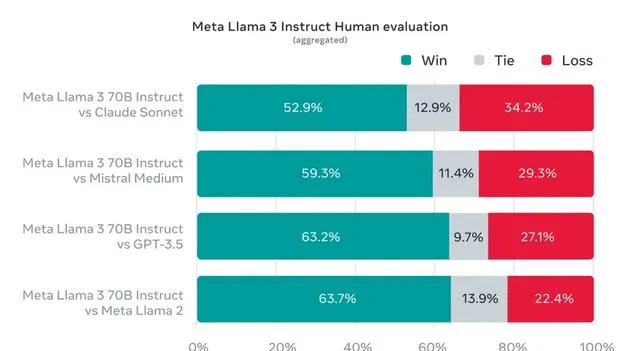
鑒於這些基準數據支持 Llama 3 的優勢,我們決定將其用於我們的生成式 AI 新聞搜尋。
一般來說,較小的模型因為不需要大量的 VRAM 並且參數計算更少,所以推理速度更快,因此我們選擇使用較小的 Llama 3 模型,即 Llama 3 8B 模型。
開始編碼。
新聞 API
我們將利用 Newsdata.io 提供的免費新聞 API 根據搜尋查詢獲取新聞內容。我們也可以使用來自 Google 的 RSS 源,或者其他任何新聞 API 來實作這一點。
你可以透過 API 令牌存取 Newsdata 新聞 API,這個令牌可以在 Newsdata 平台註冊後獲得。一旦我們拿到 API 令牌,就只需要發起一個帶有搜尋查詢的 GET 請求,獲取結果,並將其傳遞給 LLM。
下面是我們用來透過 Newsdata.io API 獲取新聞的程式碼片段。
# news.pyimport osimport httpxfrom configs import NEWS_API_KEY, NEWS_BASE_URLasync def getNews(query: str, max_size: int = 8): async with httpx.AsyncClient(timeout=60) as client: response = await client.get( os.path.join(NEWS_BASE_URL, "news") + f"?apiKey={NEWS_API_KEY}&q={query}&size={max_size}") try: response.raise_for_status() return response.json() except httpx.HTTPStatusError as e: print( f"Error resposne {e.response.status_code} while requesting {e.request.url!r}" ) return None
我們使用 httpx 庫異步呼叫 API,傳入 API 令牌和搜尋詞。如果響應狀態碼是 200,我們返回響應,否則打印異常資訊並返回 None。
Groq 介面
Groq 透過透過 API 金鑰進行身份驗證的 REST API 提供 Llama 3 8B 模型。我們還可以透過官方的 Groq Python 庫與 Llama 3 8B 模型進行互動。
以下是我們將如何與 Groq 進行互動。
Groq 透過 REST API 提供 Llama 3 8B 模型,並透過 API 金鑰進行認證。我們還可以透過官方的 Groq Python 庫與 Llama 3 8B 模型進行互動。
下面是我們如何使用 Groq。
# llms/groq.pyfrom groq import Groq, AsyncGroqimport tracebackfrom typing import List, Dict, Unionfrom llms.base import BaseLLMfrom llms.ctx import ContextManagementfrom groq import RateLimitErrorimport backoffmanageContext = ContextManagement() class GroqLLM(BaseLLM): def __init__(self, api_key: Union[str, None] = None): super().__init__(api_key) self.client = AsyncGroq(api_key=api_key) @backoff.on_exception(backoff.expo, RateLimitError, max_tries=3) async def __call__(self, model: str, messages: List[Dict], **kwargs): try: if "system" in kwargs: messages = [{ "role": "system", "content": kwargs.get("system") }] + messages del kwargs["system"] if "ctx_length" in kwargs: del kwargs["ctx_length"] messages = manageContext(messages, kwargs.get("ctx_length", 7_000)) output = await self.client.chat.completions.create( messages=messages, model=model, **kwargs) return output.choices[0].message.content except RateLimitError: raise RateLimitError except Exception as err: print(f"ERROR: {str(err)}") print(f"{traceback.format_exc()}") return "" class GroqLLMStream(BaseLLM): def __init__(self, api_key: Union[str, None] = None): super().__init__(api_key) self.client = AsyncGroq(api_key=api_key) async def __call__(self, model: str, messages: List[Dict], **kwargs): if "system" in kwargs: # print(f"System in Args") messages = [{ "role": "system", "content": kwargs.get("system") }] + messages del kwargs["system"] # print(f"KWARGS KEYS: {kwargs.keys()}") messages = manageContext(messages, kwargs.get("ctx_length", 7_000)) if "ctx_length" in kwargs: del kwargs["ctx_length"] output = await self.client.chat.completions.create(messages=messages, model=model, stream=True, **kwargs) async for chunk in output: # print(chunk.choices[0]) yield chunk.choices[0].delta.content or ""
我習慣於讓 LLM 類從 BaseLLM 繼承,這樣可以透過基礎類別控制所有常見的功能。下面是 BaseLLM 的定義。
# llms/base.pyfrom abc import ABC, abstractmethodfrom typing import List, Dict, Union class BaseLLM(ABC): def __init__(self, api_key: Union[str, None] = None, **kwargs): self.api_key = api_key self.client = None self.extra_args = kwargs @abstractmethod async def __call__(self, model: str, messages: List[Dict], **kwargs): pass
使用 Llama 3 8B 模型,我們可以在上下文長度中使用 8192 個詞元。其中我們將 7000 個詞元用於輸入上下文,其余用於輸出或生成。
如果輸入上下文超過 7000 個詞元,那麽我們需要管理這個上下文,以便為輸出生成保留足夠的詞元。為此,我們編寫了下面的 ContextManagement 工具。
# llms/ctx.pyfrom typing import List, Dict, Literal, Unionfrom transformers import AutoTokenizer class ContextManagement: def __init__(self): # assert "mistral" in model_name, "MistralCtx only available for Mistral models" self.tokenizer = AutoTokenizer.from_pretrained( "meta-llama/Meta-Llama-3-8B") def __count_tokens__(self, content: str): tokens = self.tokenizer.tokenize(content) return len(tokens) + 2 def __pad_content__(self, content: str, num_tokens: int): return self.tokenizer.decode( self.tokenizer.encode(content, max_length=num_tokens)) def __call__(self, messages: List[Dict], max_length: int = 28_000): managed_messages = [] current_length = 0 current_message_role = None for ix, message in enumerate(messages[::-1]): content = message.get("content") message_tokens = self.__count_tokens__(message.get("content")) if ix > 0: if current_length + message_tokens >= max_length: tokens_to_keep = max_length - current_length if tokens_to_keep > 0: content = self.__pad_content__(content, tokens_to_keep) current_length += tokens_to_keep else: break if message.get("role") == current_message_role: managed_messages[-1]["content"] += f"\\n\\n{content}" else: managed_messages.append({ "role": message.get("role"), "content": content }) current_message_role = message.get("role") current_length += message_tokens else: if current_length + message_tokens >= max_length: tokens_to_keep = max_length - current_length if tokens_to_keep > 0: content = self.__pad_content__(content, tokens_to_keep) current_length += tokens_to_keep managed_messages.append({ "role": message.get("role"), "content": content }) else: break else: managed_messages.append({ "role": message.get("role"), "content": content }) current_length += message_tokens current_message_role = message.get("role") # print(managed_messages) print(f"TOTAL TOKENS: ", current_length) return managed_messages[::-1]
我們使用 HuggingFace 的 tokenizers 庫來對我們的訊息進行標記化和計算詞元,並只保留符合我們之前設定的最大詞元長度(7000)的訊息內容。
要使用 meta-llama/Meta-Llama-3–8B 分詞器,我們首先需要在 HuggingFace 上提供我們的詳細資訊並接受 Meta 提供的使用條款,並透過使用 huggingface-cli login 命令或在 AutoTokenizer 的 from_pretrained 方法中提供 token 將我們的 HuggingFace token 添加到我們的機器上。
提示詞
我們將使用一個非常簡單的提示來進行我們的生成式 AI 新聞搜尋套用。提示如下。
# prompts.pySYSTEM_PROMPT = """You are a news summary bot. When a user provides a query, you will receive several news items related to that query. Your task is to assess the relevance of these news items to the query and retain only the ones that are pertinent.If there are relevant news items, you should summarize them in a concise, professional, and respectful manner. The summary should be delivered in the first person, and you must provide citations for the news articles in markdown format. Do not inform the user about the number of news items reviewed or found; focus solely on delivering a succinct summary of the relevant articles.In cases where no relevant news items can be found for the user's query, respond politely stating that you cannot provide an answer at this time. Remember, your responses should directly address the user's interest without revealing the backend process or the specifics of the data retrieval.For example, if the query is about "Lok Sabha elections 2024" and relevant articles are found, provide a summary of these articles. If the articles are unrelated or not useful, inform the user respectfully that you cannot provide the required information."""
提示非常直接易懂。
代理
讓我們把所有的部份整合起來,完成我們的生成式 AI 新聞搜尋代理。
# agent.pyfrom llms.groq import GroqLLMStreamfrom configs import GROQ_API_KEY, GROQ_MODEL_NAMEfrom news import getNewsfrom prompts import SYSTEM_PROMPTllm = GroqLLMStream(GROQ_API_KEY)async def newsAgent(query: str): retrieved_news_items = await getNews(query) if not retrieved_news_items: yield "\\n_無法獲取與搜尋查詢相關的新聞。_"" return retrieved_news_items = retrieved_news_items.get("results") useful_meta_keys = [ "title", "link", "keywords", "creator", "description", "country", "category" ] news_items = [{ k: d[k] for k in useful_meta_keys } for d in retrieved_news_items] messages = [{ "role": "user", "content": f"查詢: {query}\\n\\n新聞條目: {news_items}" }] async for chunk in llm(GROQ_MODEL_NAME, messages, system=SYSTEM_PROMPT, max_tokens=1024, temperature=0.2): yield chunk
上面我們匯入了與 Groq 上的 Llama 3 互動、上下文管理、系統提示和新聞檢索所需的所有模組。接著,我們定義了 newsAgent 函式,這個函式接受使用者的查詢作為唯一參數。
在 newsAgent 中,我們首先透過 Newsdata.io API 檢索新聞,然後選擇我們想要傳遞給 LLM 的相關鍵值。然後我們將查詢、檢索到的新聞項和系統提示連同模型名稱傳遞給我們的流式 Groq 介面,並隨著它們生成和接收時產生數據塊。
環境變量和配置
我們需要設定以下環境變量來執行我們的生成式 AI 新聞搜尋應用程式。
環境變量
GROQ_API_KEY="YOUR_GROQ_API_KEY"GROQ_MODEL_NAME="llama3-8b-8192"NEWS_API_KEY="YOUR_NEWS_API_KEY"NEWS_BASE_URL="<https://newsdata.io/api/1/>"
我們需要 Groq API 金鑰和 Newsdata.io 的 API 金鑰來檢索新聞。
載入環境變量
import osfrom dotenv import load_dotenvload_dotenv()GROQ_API_KEY = os.environ.get("GROQ_API_KEY")GROQ_MODEL_NAME = os.environ.get("GROQ_MODEL_NAME")NEWS_API_KEY = os.environ.get("NEWS_API_KEY")NEWS_BASE_URL = os.environ.get("NEWS_BASE_URL")
暴露 API
我們的生成式 AI 新聞搜尋代理幾乎準備就緒。我們只需要透過流式 API 暴露它。為此,我們將使用 FastAPI 和 Uvicorn,如下面的程式碼所示。
# app.pyfrom fastapi import FastAPIfrom fastapi.responses import StreamingResponsefrom fastapi.middleware.cors import CORSMiddlewareimport uvicornfrom agent import newsAgentapp = FastAPI()origins = ["*"]app.add_middleware( CORSMiddleware, allow_origins=origins, allow_credentials=True, allow_methods=["*"], allow_headers=["*"],)@app.get("/")async def index(): return {"ok": True}@app.get("/api/news")async def api_news(query: str): return StreamingResponse(newsAgent(query), media_type="text/event-stream")if __name__ == "__main__": uvicorn.run("app:app", host="0.0.0.0", port=8899, reload=True)
上面,我們匯入了我們的 newsAgent 以及所需的 FastAPI 和 Uvicorn 模組,並設定了 FastAPI 應用程式。
我們建立了一個索引端點僅用於健康檢查。我們的新聞搜尋代理透過 /api/news 路由暴露,該路由返回流式響應。
完成 app.py 檔後,我們可以使用以下命令啟動伺服器。
python app.py
伺服器將在埠號 8899 上啟動。
我們現在可以在瀏覽器上轉到 http://localhost:8899/api/news?query=searchtext 並以以下方式獲取我們的新聞。
整個程式碼庫可在下面提供的連結中找到。
GitHub - GenAINewsAgent:https://github.com/mcks2000/llm_notebooks/tree/main/agent/GenAINewsAgent
總結
在本篇部落格中,我們展示了如何透過 Groq 提供的快速 LPU(語言處理單元)介面實作近乎即時的推理。我們還瞥見了 Llama 3 在基準測試中的出色表現,並將小型版 Llama 3 8B 模型整合進了新聞摘要功能中。
資源:
點贊關註 二師兄 talk 獲取更多資訊,並在 頭條 上閱讀我的短篇技術文章











