

最近的Charls資料庫風頭正盛,可謂是真正的「國貨之光」人的!用別人的數據進行二次挖掘,找好選題下載數據,加上統計學方法得出結果就能寫文章,這誰能不心動?今天分享的這篇文章就是用Charls資料庫,用上一個新指標- 胰島素抵抗 ,就又發文一區!
2024年6月6日,中國學者用 Charls資料庫 做了一項研究,在期刊 【Cardiovascular Diabetology 】 ( 醫學一區top,IF=9.3 ) 發表了題為:「Insulin resistance assessed by estimated glucosedisposal rate and risk of incident cardiovascular diseases among individuals without diabetes: findings from a nationwide, population based, prospective cohort study」的研究論文,近年來的研究表明, 胰島素抵抗(IR)與心血管疾病(CVD)的發生有關,而葡萄糖處置率(eGDR)被認為是胰島素抵抗的可靠替代指標。 本研究 旨在探討eGDR與非糖尿病參與者CVD發病率的關系。

胰島素抵抗(IR)作為多種慢性疾病發病的共同土壤,危害巨大。近年來又有多項研究表明,胰島素抵抗(IR)與心血管疾病(CVD)的發生有關。但先前大多數研究都涉及糖尿病患者,可能會導致結果不準確。
1.研究設計
本研究采用了 中國健康與養老追蹤調查(Charls)資料庫2011-2020年 的數據,經過納排,最終納入了 5512名 年齡>45歲沒有心血管疾病和糖尿病,但基線時有完整的eGDR數據符合條件的參與者。
生化參數包括 :高敏C反應蛋白(hsCRP)、血尿素氮(BUN)、血清肌酐、糖化血紅蛋白A1c(HbA1c)和血脂譜。
高血壓 定義為:基於醫生診斷和/或任何抗高血壓藥物使用和/或血壓≥140/90mmHg的自我報告的高血壓。
糖尿病 定義為:依據醫生自我報告的診斷、降糖藥物的使用或FBG≥126mg/dL和/或基線時HbA1c水平≥6.5%。
腎臟疾病 定義為:自我報告的醫生診斷和估計腎小球濾過率<60ml/min/1.73m2 。
體重指數(BMI) 計算公式為:BMI(kg/m2 )=體重/身高2, BMI ≥ 28 kg/m2 為肥胖。
本研究的暴露是基線時的 eGDR。 eGDR (mg/kg/min) = 21.158 − (0.09 × 腰圍) − (3.407 × 高血壓) − (0.551 × HbA1c) [腰圍 (cm)、高血壓 (yes = 1/no = 0) 和 HbA1c (%)]。
主要結局 是心血管疾病,包括心臟病和中風。
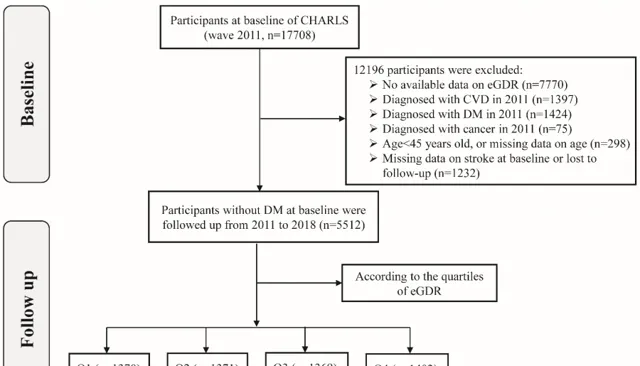
2.基線數據
該研究共納入 5512 名 參與者,其中女性占54.1%,並根據 eGDR 的四分位數 (Q) 進一步分為四個亞組。
平均年齡、女性比例、收縮壓、舒張壓、BMI、腰圍、血紅蛋白水平、HbA1c、TC、TG、LDL、UA 和 hsCRP 水平 均隨 eGDR 的增加而降低 (均 P < 0.001)。
然而, eGDR水平較高的人往往生活在農村和南部地區,吸煙的占比較高。
在eGDR第四分位數,酒精消費比例最高(42.7%)。
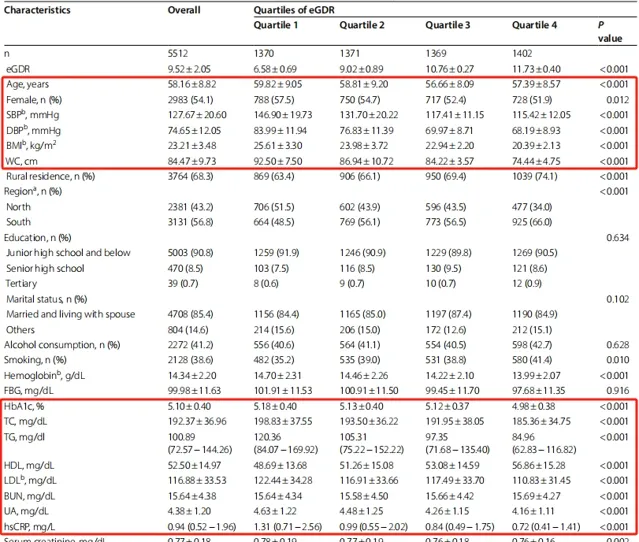
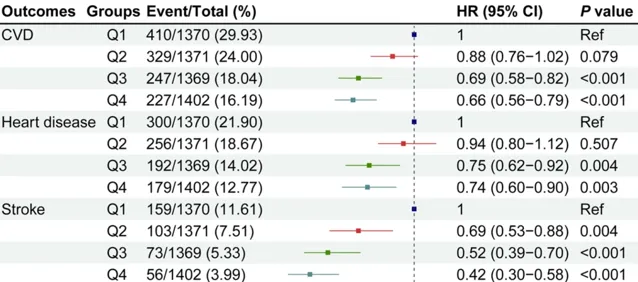
3.觀察性研究發現eGDR與CVD疾病之間存在關聯
eGDR和CVD之間的劑量-反應曲線如下圖所示, RCS曲線表明,無論是否調整協變量,eGDR 與 CVD、心臟病和卒中發病率之間存在顯著的線性關系 (總體P均為 < 0.001,非線性P > 0.05)。
在完全調整協變量(模型 3)後, eGDR 每增加 1.0 SD,心血管疾病風險降低 17% (HR:0.83,95% CI:0.78 − 0.89), 心臟病風險降低 13% (HR:0.87,95% CI:0.81 − 0.94), 卒中風險降低 30% (HR:0.63 − 0.78)。

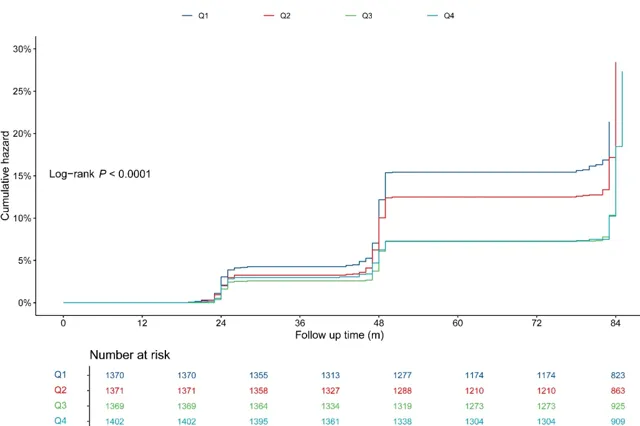
Kaplan-Meier生存曲線
表明,eGDR較高的個體CVD、心臟病和卒中的累積發病率較低。
使用Cox比例風險回歸模型得出的結果 與先前一致。
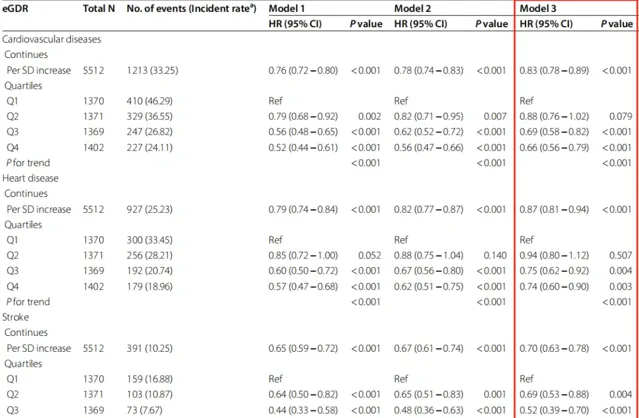
模型2:調整了年齡、性別、農村居住、婚姻狀況、教育程度、吸煙、飲酒狀況;
模型3:在模型2的基礎上進一步調整地區、TC(總膽固醇)、HDL(高密度脂蛋白)、TG(甘油三酯)、LDL(低密度脂蛋白)、BUN(血尿素氮)、UA(尿酸)、hsCRP(高敏c反應蛋白)、血紅蛋白、慢性腎臟疾病、肥胖;
a 每1000人年隨訪的發生率。
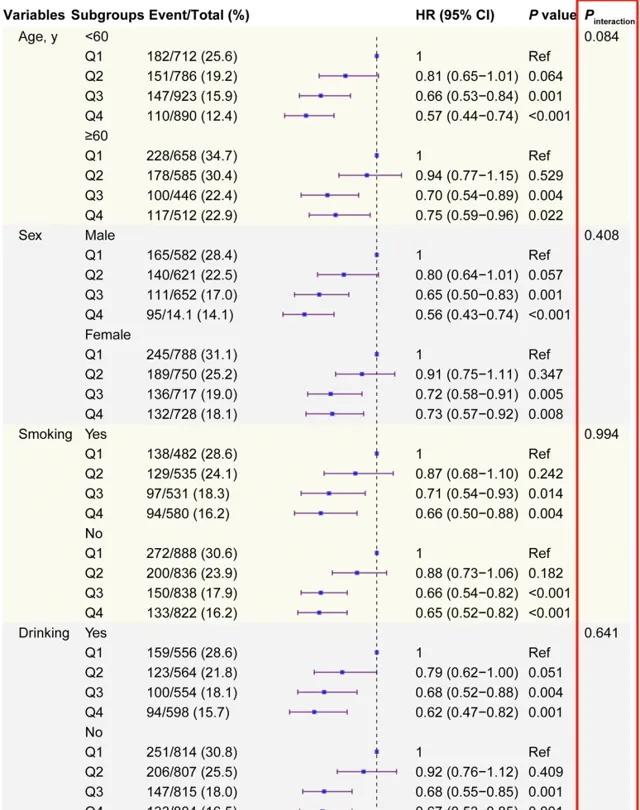
4.亞組分析結果
研究團隊使用 亞組分析 ,用於評估 eGDR(連續和分類)與 CVD 發病率之間的關聯是否被預先指定的亞組所改變。
在大多數亞組中, eGDR與CVD發病率之間的關系與主要結果一致 。 eGDR 對 CVD 發病率的預測效能僅透過吸煙亞組進行修改(交互作用的 P = 0.012)。

同時,在這些亞組中, 未觀察到eGDR四分位組與不同終點發生率之間的顯著互動作用。
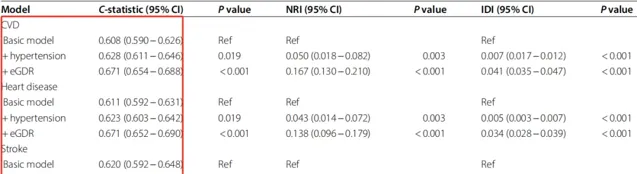
5.納入eGDR評估其對的CVD預測價值
基於Model 3,研究團隊構建了基本模型(包括年齡、性別、農村居住地、婚姻狀況、教育程度、吸煙情況、飲酒狀況、地區、TC、HDL、TG、LDL、BUN、UA、hsCRP、血紅蛋白、慢性腎臟病和肥胖)。
在添加eGDR後,顯著最佳化了CVD (C統計量:0.671 vs. 0.608,P < 0.001)、 心臟病 (C統計量:0.671 vs. 0.611,P < 0.001)和 卒中 (C統計量:0.685 vs. 0.620 P < 0.001) 基本模型的預測能力。
此外,心血管疾病、心臟病和卒中的所有NRI和IDI均顯著(均P<0.001)。
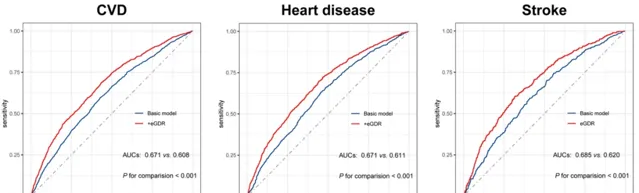
盡管將高血壓納入基本模型後,缺失增強了其對心血管結局的預測能力,但與納入 eGDR 的相比,它的強度較差。
本文使用的統計學方法主要分為以下幾部份:
1.觀察性研究
分別使用 變方分析 和 Kruskal-Wallis H 檢驗 對正態分布數據和偏態分布數據進行基線數據比較。
使用eGDR每個四分位數的中值進行了
趨勢檢驗
。
采用 多重插補法 對缺失值進行插補。
2.暴露與結局之間的關聯性分析
生成 Kaplan-Meier 曲線 來說明 CVD 的累積發病率,並使用對數秩檢驗比較差異。
擬合三個 Cox 比例風險模型 以估計 eGDR 和 CVD 之間的風險比 (HR) 以及相應的 95% 置信區間 (CI)。
使用 Schoenfeld殘留誤差檢驗 檢查模型中每個變量的比例風險假設,未觀察到違規行為。
為了研究eGDR與CVD發生率的劑量-反應關系,構建了基於Cox回歸模型的 RCS曲線 。
3.評估eGDR對CVD發病率的預測價值
建立
RCS曲線
來評估eGDR對CVD發病率的預測價值,並采用C統計量進行量化。
為了進一步估計基本模型之外的預測能力,計算了 凈重分類改進(NRI) 和 綜合歧視改善(IDI)指數。
4.亞組分析
進行 亞組分析 以評估 eGDR(連續和分類)對幾個亞組 CVD 發病率的影響,包括年齡(< / ≥ 60 歲)、性別(男性/女性)、吸煙(是/否)和飲酒(是/否)。
5.敏感性分析
進行了幾項 敏感性分析 ,以評估主要發現的穩健性。
首先,在血糖狀態正常的參與者中重復分析;
其次,根據高血壓(130/80 mm Hg) 重新定義了eGDR;
最後,在非糖尿病參與者中檢查 eGDR 與 CVD 的關聯的結果。

好的選題非常關鍵,這個Charls資料庫的新指標可要好好把握。本公眾號去年就介紹了一篇關於溫州醫科大學的學者使用Nhanes+胰島素抵抗(IR)發表SCI的文章。












