最近多模態生成領域也在「神仙打架」,比如Meta的全新訓練方法Transfusion,用單個模型就能同時生成文本和影像!
還有之前華為、清華提出的個人化多模態內容生成技術PMG,生成的內容可「量身客製」,更能滿足偏好。
這些效果炸裂的新成果證明了 多模態生成一直是研究熱門 ,更實際點的證明還有:
因此多模態生成依舊是我們非常好的選擇,想抓緊投中頂會給自己加碼的同學可以考慮。這裏為了幫助各位快速了解這個方向目前的最新動態,我整理好了 10篇 多模態生成今年最新的論文 給各位作參考,程式碼基本都有。
論文原文+開原始碼需要的同學關註「學姐帶你玩AI」公眾號,那邊回復「多模態生成」獲取。
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
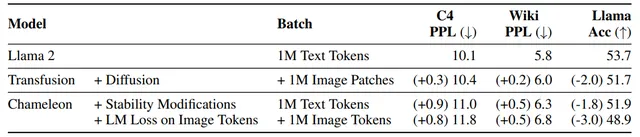
方法: 論文一個多模態模型訓練的配方Transfusion,可以處理離散數據(如文本或程式碼)和連續數據(例如影像、音訊和視訊數據)。Transfusion結合了語言建模損失函式(下一個詞預測)和擴散模型,透過單一的transformer來訓練混合模態序列,使其能夠無縫地生成離散和連續的模態,例如同時生成文本和影像。
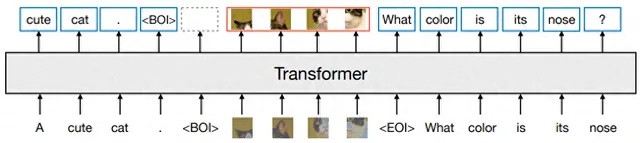
創新點:
PMG: Personalized Multimodal Generation with Large Language Models
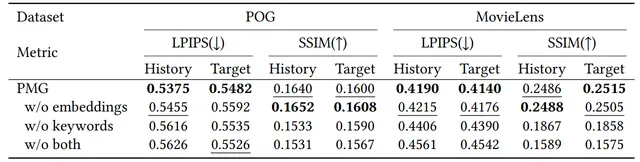
方法: 論文提出了一種基於大語言模型(LLMs)的個人化多模態生成方法(PMG),首先將使用者行為轉化為自然語言,以便LLM能夠理解並提取使用者的偏好。然後,將使用者偏好輸入生成器(如多模態LLM或擴散模型)以生成個人化內容。
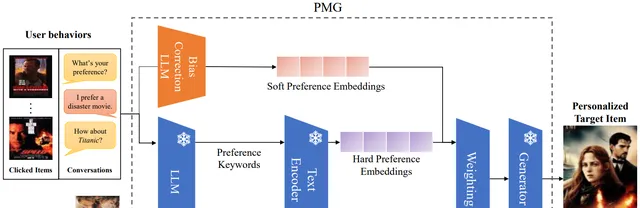
創新點:
ANOLE: An Open, Autoregressive, Native Large Multimodal Models for Interleaved Image-Text Generation
方法: ANOLE是一個開源的多模態模型,專註於交錯影像-文本生成。它基於Meta AI的Chameleon模型,透過高效微調少量參數來增強影像和多模態生成能力,而無需依賴擴散模型。
創新點:
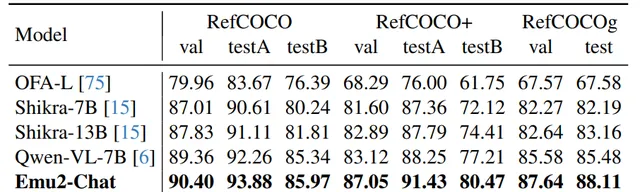
Generative Multimodal Models are In-Context Learners
方法: 論文介紹了一個名為 Emu2 的大型多模態生成模型,它透過大規模多模態序列的訓練,具備了強大的多模態上下文學習能力。Emu2 能夠處理包括文本、影像-文本對和交錯的影像-文本-視訊等在內的多種數據型別,並且在少量樣本或簡單指令的情況下解決多模態任務。

創新點:
論文原文+開原始碼需要的同學關註「學姐帶你玩AI」公眾號,那邊回復「多模態生成」獲取。











