近日
2024年高考作文題等
高考相關話題引發熱議
「AI大模型做高考題」
也成為一大看點
AI參加高考
數學能得多少分

悄悄問一句
高考數學題
你還看得懂嗎?

或許我們看不懂
但大模型可以
近日
復旦大學NLP(自然語言處理)
實驗室LLMEVAL團隊
請來13位大模型「考生」
一起做2024年高考數學真題
結果怎樣?
先說結論:
從整體來看
大模型們的「高考成績」
都不算太高
OpenAI日前釋出的
新一代旗艦大模型 GPT-4o
與阿裏雲研發的通義千問
720億參數大模型 Qwen-72b
在兩次測試中排名都靠前
正確率穩定在60%以上
部份大模型的表現
存在起伏與波動
如百川智慧、字節跳動新近釋出的
Baichuan4 和 豆包大模型
分別在新I卷和新II卷客觀題測試中
得分排名第一
但在另一場測試中
排名相對靠後
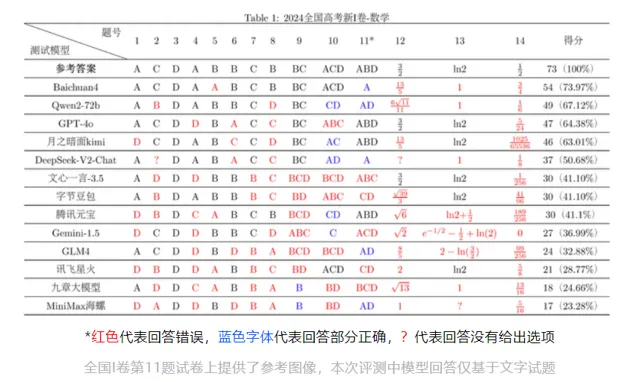
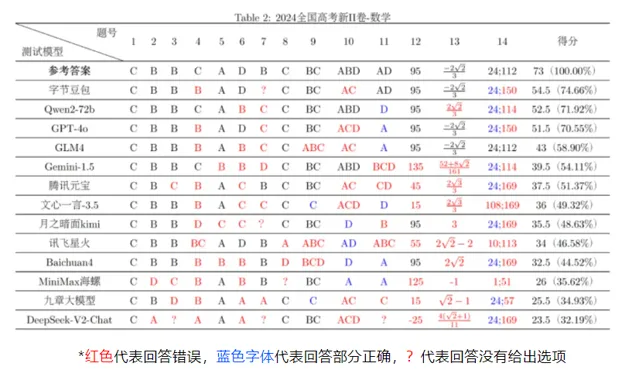
圖源:復旦大學NLP實驗室
根據兩次評測結果
該團隊發現
大部份測試大模型在 簡單題
(如選擇題前三道)
有較好的準確率
而在 中檔題 中表現一般
對於 較難的題目
大模型們的準確率會更低
少部份題目甚至出現
「全軍覆滅」的情況
人工智慧這麽「聰明」
為什麽還會出錯?
AI為什麽會 把題做錯
測試發現
讓AI大模型做數學題
仍是一個難度較大的挑戰

首先
文本輸入格式 的不同
會對測試結果造成
比較明顯的幹擾
目前測試主要采用
上傳圖片 辨識 文本 的方式
這種方式更類似「人類」
是對大模型能力的全面考驗
有的大模型還未做題
就先敗在了AI識圖這一步
其次
大模型的 推理能力
仍有很大進步空間
較難的題目
對思維能力的考察要求更高
大模型的準確率也會更低
此外
在多選題方面
大多數模型表現不佳
可見,面臨 復雜選項 的時候
大模型的準確率也會降低

雖然在解題方面
AI大模型的短期表現
還達不到完美
但在攻克數學問題的路上
AI的每一次進步
都是對未來教育想象空間的開拓
值得更多耐心與期待
撰文/排版:李汶鍵 編輯:李飛 統籌:李政葳
參考丨復旦大學NLP實驗室、澎湃新聞、機器之心、量子位











