關註並星標
從此不迷路
電腦視覺研究院
公眾號ID | ComputerVisionGzq
電腦視覺研究院專欄
目標檢測被認為是電腦視覺領域中最具挑戰性的問題之一,因為它涉及場景中物件 分類和物件定位的組合。今天分享這個框架有點陳舊,但精髓!
一、前言
目標檢測被認為是電腦視覺領域中最具挑戰性的問題之一 ,因為它涉及場景中物件分類和物件定位的組合。最近,與其他方法相比,深度神經網路 (DNN) 已被證明可以實作卓越的目標檢測效能,其中YOLOv2是基於DNN的最先進技術之一。

目標檢測方法在速度和準確性方面。盡管YOLOv2可以在強大的GPU上實作即時效能,但在計算能力和記憶體有限的嵌入式計算裝置上利用這種方法進行視訊中的即時目標檢測仍然非常具有挑戰性。
二、概要
在今天分享中,有研究者提出了一個名為 Fast YOLO 的新框架,這是一個快速的You Only Look Once框架,它可以加速YOLOv2以便能夠以即時方式在嵌入式裝置上執行視訊中的目標檢測。
首先,利用前進演化深度智慧框架來前進演化YOLOv2網路架構,並產生一個最佳化的架構(這裏稱為O-YOLOv2),其 參數減少了2.8倍 , IOU下降了約2% 。為了在保持效能的同時進一步降低嵌入式裝置的功耗,在提出的Fast YOLO框架中引入了一種 運動自適應推理方法 ,以降低基於時間運動特性的O-YOLOv2深度推理的頻率。實驗結果表明,與原始YOLOv2相比,所提出的Fast YOLO框架可以將 深度推理的數量平均減少38.13% , 視訊中目標檢測的平均加速約為3.3倍 ,導致Fast YOLO執行在Nvidia Jetson TX1嵌入式系統上平均約為18FPS。
三、新框架
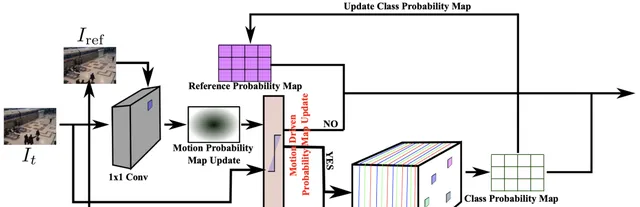
提出的Fast YOLO框架分為兩個主要部份:i)最佳化的YOLOv2架構,以及ii運動自適應推理(見上圖)。對於每個視訊幀,由帶有參考幀的視訊幀組成的影像堆疊被傳遞到1×1摺積層。摺積層的結果是一個運動機率圖,然後將其送入運動自適應推理模組以確定是否需要深度推理來計算更新的類機率圖。正如介紹中提到的,主要目標是引入一個視訊中的目標檢測框架,該框架可以在嵌入式裝置上更快地執行,同時減少資源使用,從而顯著降低功耗。透過利用這種運動自適應推理方法,深度推理的頻率大大降低,並且僅在必要時執行。

深度神經網路的主要挑戰之一,尤其是在將它們用於嵌入式場景時,是網路架構設計。設計過程通常由人類專家執行,他探索大量網路配置,以在建模精度和參數數量方面為特定任務找到最佳架構。尋找最佳化的網路架構目前通常作為超參數最佳化問題來解決,但這種解決問題的方法非常耗時,而且大多數方法對於大型網路架構來說要麽在計算上難以處理,要麽導致次優解決方案不夠嵌入式使用。
例如,超參數最佳化的一種常用方法是網格搜尋,其中檢查大量不同的網路配置,然後選擇最佳配置作為最終的網路架構。然而,為視訊中的目標檢測而設計的深度神經網路(如YOLOv2)具有大量參數,因此在計算上難以搜尋整個參數空間以找到最佳解決方案。
因此,研究者沒有利用超參數最佳化方法來獲得基於YOLOv2的最佳網路架構,而是利用專為提高網路效率而設計的網路最佳化策略。特別是,研究者利用前進演化深度智慧框架來最佳化網路架構,以合成滿足嵌入式裝置記憶體和計算能力限制的深度神經網路。

為了進一步降低處理器單元的功耗,用於視訊中的嵌入式目標檢測,研究者利用了這樣一個事實,即並非所有捕獲的視訊幀都包含唯一資訊,因此不需要對所有幀進行深度推理。因此,研究者引入了一種運動自適應推理方法來確定特定視訊幀是否需要深度推理。透過在必要時使用前面介紹的O-YOLOv2網路進行深度推理,這種運動自適應推理技術可以幫助框架減少對計算資源的需求,從而顯著降低功耗系統以及處理速度的提高。
四、實驗
原始YOLOv2網路架構與最佳化後的YOLOv2之間的架構和效能比較
提出的Fast YOLO、O-YOLOv2和原始YOLOv2在Nvidia Jetson TX1嵌入式系統上執行的平均執行時效能和深度推理頻率。

END
轉載請聯系本公眾號獲得授權
電腦視覺研究院學習群等你加入!
ABOUT
電腦視覺研究院
電腦視覺研究院主要涉及深度學習領域,主要致力於目標檢測、目標跟蹤、影像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的論文演算法新框架,提供論文一鍵下載,並分享實戰計畫。研究院主要著重」技術研究「和「實踐落地」。研究院會針對不同領域分享實踐過程,讓大家真正體會擺脫理論的真實場景,培養愛動手編程愛動腦思考的習慣!
🔗











