關註並星標
從此不迷路
電腦視覺研究院
公眾號ID | ComputerVisionGzq
論文地址: https://arxiv.org/pdf/2112.13082.pdf
電腦視覺研究院專欄
作者:Edison_G
多尺度特征融合!
一、 前言
本文提出了一種基於單模態語意分割的新型坑窪檢測方法。它首先使用摺積神經網路從輸入影像中提取視覺特征,然後通道註意力模組重新加權通道特征以增強不同特征圖的一致性。隨後,研究者采用了一個 空洞空間金字塔池化模組 (由串聯的空洞摺積組成,具有漸進的擴張率)來整合空間上下文資訊。
這有助於更好地區分坑窪和未損壞的道路區域。最後,使用研究者提出的多尺度特征融合模組融合相鄰層中的特征圖, 這 進一步減少了不同特征通道層之間的語意差距 。在Pothole-600數據集上進行了大量實驗,以證明提出的方法的有效性。定量比較表明,新提出的方法在RGB影像和轉換後的視差影像上均達到了最先進的 (SoTA) 效能,優於三個SoTA單模態語意分割網路。
二、 前言
在最先進的(SoTA)語意分割CNN中,全摺積網路(FCN)用摺積層替換了傳統分類網路中使用的全連線層,以獲得更好的分割結果。上下文資訊融合已被證明是一種有效的工具,可用於提高分割精度。ParseNet透過連線全域池化特征來捕獲全域上下文。PSPNet引入了空間金字塔池化(SPP)模組來收集不同尺度的上下文資訊。Atrous SPP(ASPP)套用不同的空洞摺積來捕獲多尺度上下文資訊,而不會引入額外的參數。
三、 新框架
給定道路影像,坑窪可以具有不同的形狀和尺度。我們可以透過一系列的摺積和池化操作獲得頂層的特征圖。雖然特征圖具有豐富的語意資訊,但其分辨率不足以提供準確的語意預測。不幸的是,直接結合低階特征圖只能帶來非常有限的改進。為了克服這個缺點,研究者設計了一個有效的特征融合模組。
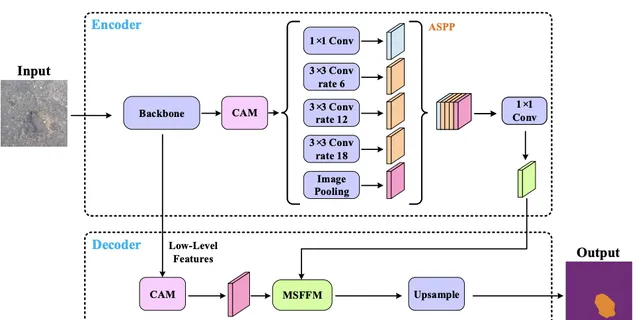
研究者提出的道路坑窪檢測網路的架構如上圖所示。首先,采用預訓練的dilated ResNet-101作為主幹來提取視覺特征,還在最後兩個ResNet-101塊中用空洞摺積替換下采樣操作,因此最終特征圖的大小是輸入影像的1/8。
該模組有助於在不引入額外參數的情況下保留更多細節。此外,采用Deeplabv3中使用的ASPP模組來收集頂層特征圖中的上下文資訊。然後,采用CAM重新加權不同通道中的特征圖。它可以突出一些特征,從而產生更好的語意預測。最後,將不同級別的特征圖輸入到MSFFM中,以提高坑窪輪廓附近的分割效能。
Multi-scale feature fusion
頂部特征圖具有豐富的語意資訊,但其分辨率較低,尤其是在坑窪邊界附近。另一方面,較低的特征圖具有低階語意資訊但分辨率更高。為了解決這個問題,一些框架直接將不同層的特征圖組合起來。然而,由於不同尺度的特征圖之間的語意差距,他們取得的改進非常有限。
註意模組已廣泛套用於許多工作中。受一些成功套用的空間註意力機制的啟發,研究者引入了MSFFM,它基於空間註意力來有效地融合不同尺度的特征圖。
語意差距是特征融合的關鍵挑戰之一
。
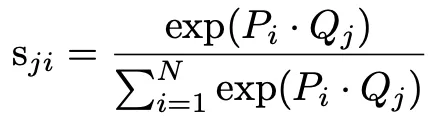
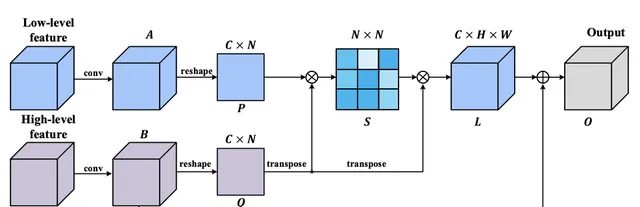
為了解決這個問題,MSFFM透過矩陣乘法計算不同特征圖中像素之間的相關性,然後將相關性用作更高級別特征圖的權重向量。
總之,研究者利用矩陣乘法來測量來自不同層的特征圖中像素的相關性,將來自較低特征圖的詳細資訊整合到最終輸出中,從而提高了坑洞邊界的語意分割效能。在最後兩層之間套用這個模組。
Channel-wise feature reweighing
眾所周知,高級特征具有豐富的語意資訊,每個通道圖都可以看作是一個特定類別的響應。每個響應都會在不同程度上影響最終的語意預測。因此,研究者利用CAM,如下圖所示,透過改變每個通道中的特征權重來增強每一層中特征圖的一致性。
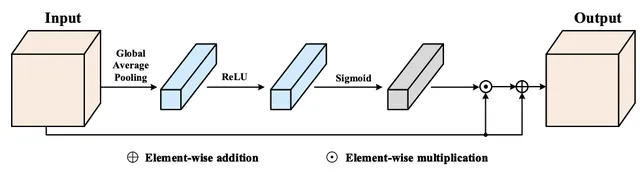
CAM旨在根據每個特征圖的整體像素重新加權每個通道。首先采用全域平均池化層來壓縮空間資訊。隨後,使用修正線性單元(ReLU)和sigmoid函式生成權重向量,最終透過逐元素乘法運算將權重向量與輸入特征圖組合以生成輸出特征圖。整體資訊被整合到權重向量中,使得特征圖更可靠,坑窪檢測結果更接近GT實況。在最終的實驗中,在第4層和第5層使用了CAM。
四、實驗及視覺化
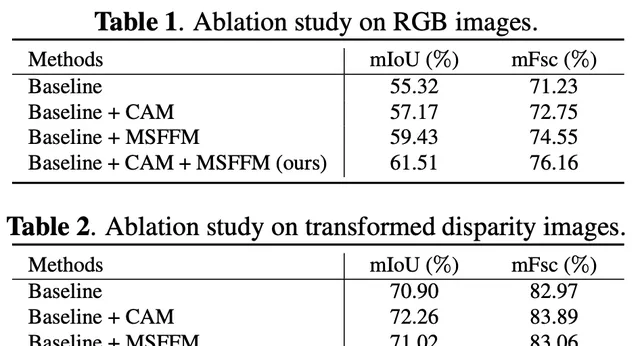
*baseline network使用的是Deeplabv3
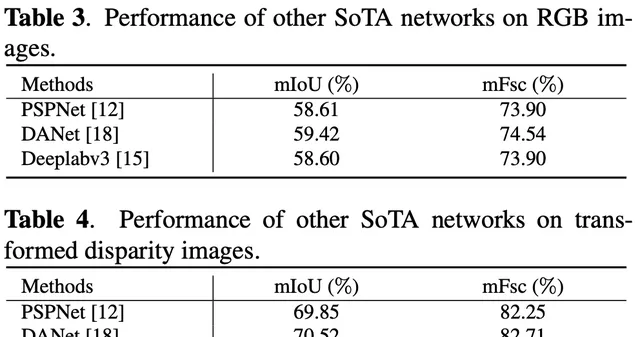
效能比較

坑窪檢測結果範例:(a) RGB影像;(b)轉換後的視差影像;(c)坑窪地面真相;(d)語意RGB影像分割結果;(e)語意變換視差影像分割結果。
在上圖中提供了提出的道路坑窪檢測方法的一些定性結果,其中可以觀察到CNN在轉換後的視差影像上取得了準確的結果。從綜合實驗評估中獲得的結果證明了新提出的方法與其他SoTA技術相比的有效性和優越性。由於提出了CAM和MSFFM,新方法在RGB和轉換後的視差影像上實作了更好的坑窪檢測效能。
© The Ending
轉載請聯系本公眾號獲得授權
電腦視覺研究院學習群等你加入!
電腦視覺研究院 主要涉及 深度學習 領域,主要致力於 人臉檢測、人臉辨識,多目標檢測、目標跟蹤、影像分割等 研究方向。 研究院 接下來會不斷分享最新的論文演算法新框架,我們這次改革不同點就是,我們要著重」 研究 「。之後我們會針對相應領域分享實踐過程,讓大家真正體會 擺脫理論 的真實場景,培養愛動手編程愛動腦思考的習慣!
電腦視覺研究院
公眾號ID | ComputerVisionGzq
🔗











