
ChatGPT、Claude.ai等大模型產品就像「圖書館」一樣為我們生成各種各樣的內容。但是想更新這個圖書館裏的知識卻不太方便,經常需要漫長、費時的預訓練、蒸餾才能完成。
研究人員提出了一種具有情景記憶控制的大語言模型Larimar,這是一種類似人腦"海馬體"的"情景記憶"能力 。
Larimar主要設計了一個外部記憶模組,專門儲存獨立的即時數據,並將這些記憶有效地註入到大語言模型中,使得Larimar無需重新預訓練就能在內容生成過程中精準使用新的知識數據。
論文地址:https://arxiv.org/abs/2403.11901

Larimar核心方法
研究人員主要受到了人腦「海馬體」神經結構的啟發。海馬體在人類的多種認知過程中扮演著關鍵角色,尤其是在記憶形成、組織和檢索,以及空間導航方面。
海馬體對短期記憶轉化為長期記憶至關重要,特別是在形成新的記憶和學習新資訊的過程中,幫助將經驗和資訊從短期記憶庫存轉移到大腦的其他部份以形成長期記憶。
Larimar采用了互補學習系統理論的觀點,其中海馬體快速學習系統將樣本記錄為情景記憶,而新皮層慢速學習系統學習輸入分布的摘要統計資訊作為語意記憶。
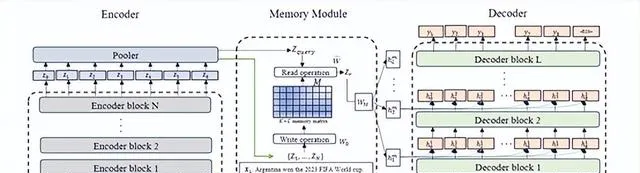
Larimar的目標是將情景記憶模組作為當前一組事實更新或編輯的全域儲存,並將這個記憶作為大語言模型解碼器的條件。為了高效且準確地更新這個記憶,研究人員利用了類似於Kanerva Machine的分層記憶結構,其中記憶體的寫入和讀取被解釋為生成模型中的推理。
此外,這種靈活的模組化設計也使得Larimar具備遺忘數據、防泄密等多種特殊記憶控制功能。
Larimar多個核心模組
1)大語言模型編碼器: Larimar使用了BERT模型作為基礎編碼器,其作用是將輸入文本對映到潛在語意空間,得到對應的向量表示數據,並作為外部"情景記憶"模組的寫入內容。
2)外部情景記憶模組 :Larimar的核心模組,設計了一個固定大小(如512x768)的儲存矩陣,用於存放編碼器輸出的潛在向量表示。該記憶模組借鑒了Kanerva的分層記憶架構思路。當有新的知識數據輸入到Larimar時,就會被寫入到情景記憶模組中,並且需要輸出時會進行隨機抽取。

3)大語言模型解碼器: 解碼器模組的作用是將情景記憶模組讀取的向量進一步解碼,生成最終的文本輸出,Larimar使用了GPT系列模型作為解碼器。解碼器透過自註意力機制將記憶模組中的數據與其他資訊整合對輸出施加影響,使得生成的文本包含了新的數據知識。

4)記憶範圍檢測器: 有時候我們期望生成的輸出不受新知識數據影響,執行原本的數據內容生成,就可以透過記憶範圍檢測器來實作。
這是一個小型序列二分類模型,根據輸入判斷是否需要利用記憶模組進行條件生成。如果檢測器輸出"無需記憶",則直接執行無條件解碼;反之則會利用新知識數據進行生成。
研究人員表示,Larimar是一種創新技術架構,可以有效解決大語言模型數據更新不及時、消除數據中存在的非法、偏見、錯誤等數據,同時可以很好保護那些敏感的數據防止外漏。











