關註並星標
從此不迷路
電腦視覺研究院
公眾號ID | ComputerVisionGzq
學習群 | 掃碼在主頁獲取加入方式
電腦視覺研究院專欄
作者:Edison_G
這次分享的以半監督目標檢測為研究物件,透過對有標簽和無標簽數據的訓練,提高了基於候選的目標檢測器(即two-stages目標檢測器)的檢測精度。 然而,由於真值標簽的不可用性,在未標記的數據上訓練目標檢測器是非常重要的。
概要
為了解決這個問題,於是就提出了一個 proposal learning方法從標記和未標記的數據中學習候選的特征和預測。該方法由自監督候選學習模組和基於一致性的候選學習模組組成。在自監督候選學習模組中,分別提出了一個候選位置損失和一個對比損失來學習上下文感知和雜訊魯棒的候選特征;在基於一致性的候選學習模組中,將一致性損失套用於候選的邊界框分類和回歸預測,以學習雜訊穩健的候選特征和預測。
最後,在COCO數據集上對所有可用的有標簽和無標簽數據進行了實驗。結果表明,新方法一致地提高了全監督基線的精度。特別是在結合了數據蒸餾之後,新方法與全監督基線和數據蒸餾基線相比,平均提高AP約2.0%和0.9%。
新框架
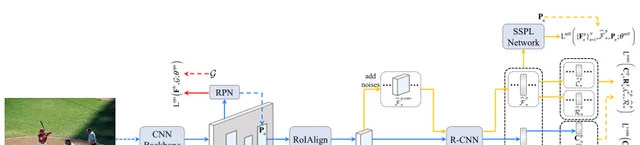
Problem Definition
在半監督目標檢測( Semi-Supervised Object Detec-
tion (SSOD) ) 中,一組標記數據D_l={(I,G)}和一組 給出了未標記數據的D_u={I},其中I和G分別表示影像和真值標簽。在目標檢測中,G由一組具有位置和目標類的物件組成。SSOD的目標是訓練目標檢測器,包括標記數據D_l和未標記數據D_u。
The Overall Framework
對於每一個標記數據(I,G)∈D_l,根據標準的全監督損失定義訓練目標檢測器是簡單的,如下公式:
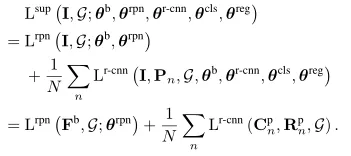
其中第二項分別表示RPN損失和R-CNN損失。該損失在反向傳播過程中最佳化θb、θrpn、θr-cnn、θcls、θreg去訓練目標檢測器。有關損失函式的更多詳細資訊,請參見:
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE transactions on pattern analysis and machine intelligence, 39(6):1137–1149, 2017
將上面公式中定義的標準全監督損失套用於標記數據dL,將自監督候選學習損失Lself和基於一致性的候選學習損失Lcons套用於未標記數據dU。透過最佳化反向傳播過程中的損失方程式中的θb,θrpn,θr-cnn,θcls,θreg,θself,對目標檢測器進行了訓練:

然後將總損失寫成如下:
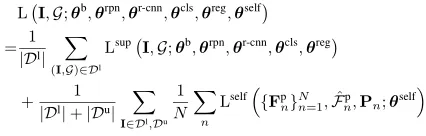
Self-Supervised Proposal Learning
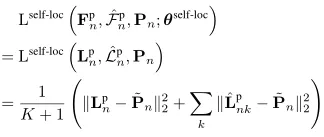
為了計算對比損失,使用instance discrimination作為pretext task:
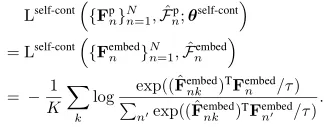
結合上面的兩個公式中的候選位置損失以及對比損失,自監督的候選學習損失寫為:
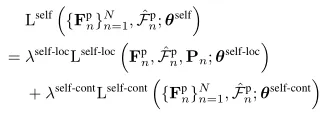
Consistency-Based Proposal Learning
為了進一步訓練抗雜訊目標檢測器,套用一致性損失來確保雜訊候選預測與其原始候選預測之間的一致性。更準確地說,將一致性損失套用於邊界框分類和回歸預測。對於邊界框分類預測C的一致性損失,使用KL散度作為損失,以強制雜訊候選的類預測及其原始候選一致。
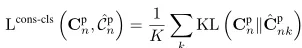
為了進一步確保候選預測的一致性,在下列公式中計算一致性損失,以強制來自雜訊候選的目標位置預測及其原始候選一致:
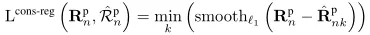
結合上面的兩個公式,基於一致性的候選 學習損失如下:

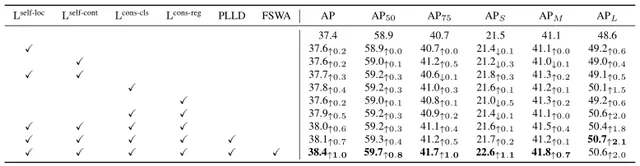
實驗

© THE END
轉載請聯系本公眾號獲得授權
電腦視覺研究院學習群等你加入!
ABOUT
電腦視覺研究院
電腦視覺研究院主要涉及深度學習領域,主要致力於人臉檢測、人臉辨識,多目標檢測、目標跟蹤、影像分割等研究方向。研究院接下來會不斷分享最新的論文演算法新框架,我們這次改革不同點就是,我們要著重」研究「。之後我們會針對相應領域分享實踐過程,讓大家真正體會擺脫理論的真實場景,培養愛動手編程愛動腦思考的習慣!
VX:2311123606











