金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
谷歌罕見open的AI,給開源大模型到底帶來了什麽?
Gemma 從釋出到現在已經時過數日,谷歌久違的這次開源,可謂是給全球科技圈投下了一枚重磅炸彈。
在最初釋出之際,不論是從谷歌官方還是Jeff Dean的發文來看,都強調的是Gemma 7B已經全面超越了同量級的Llama 2和Mistral。
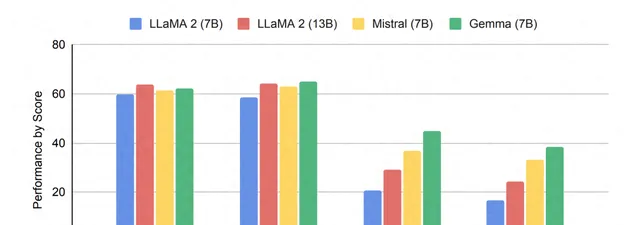
在與此前最火熱的開源大模型Llama 2在細節上做比較,不論是在綜合能力,以及推理、數學和編程等能力上,完全屬於 all win 的狀態。
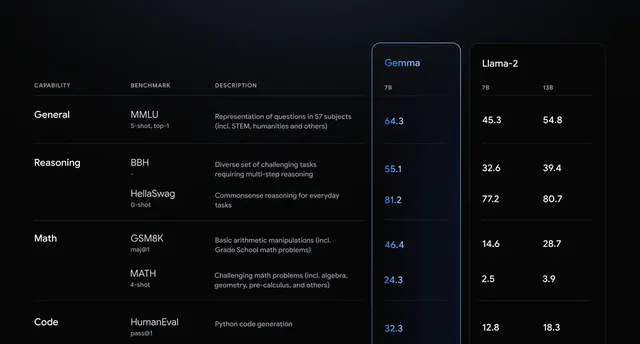
科技巨頭出品、全面對外開放、免費可商用、筆記本就能跑……各種福利標簽的加持之下,近乎讓全球的「觀眾老爺們」為之雀躍。
而就在最近,不少網友們也開始了對Gemma的各種測評。
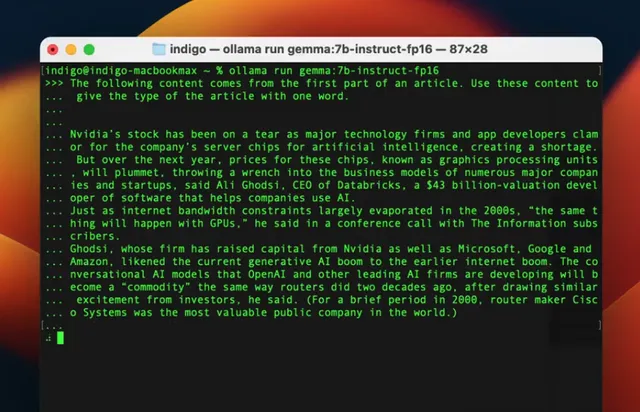
例如有人就用ollama在Macbook上跑了一下Gemma 7B,所做的任務是根據文章開頭的文字來判定文章的型別。
並在體驗過後給出了評價:
還比較穩定和準確!
還有網友在對Gemma和Mistral做了對比測試之後發現:
Gemma-7B確實能正確回答Mistral-7B回答不了的問題。

由此種種表現,網友不禁發出感慨:
谷歌打破了開源大模型的格局:形成Gemma、Llama和Mistral三足鼎立之勢。
雖然成果足以令人振奮,但似乎在開源大模型這件事上,全球的目光都還是聚焦在了國外「頂流」們的身上。
隨即而來的一個問題便是:
中國開源大模型,怎麽樣了?
在開源大模型領域,除了歐美主流科技巨頭之外,中國「選手」也是長期占有一席之地。
那麽隨著Gemma的問世,在榜單排名這件事上,是否又掀起了些許波瀾?
結果是有點意外的——
在HuggingFace的開源大模型排行榜裏, Gemma排在了7B預訓練模型的第三名 :

第一名和第二名均被國產大模型選手包攬—— InternLM2 (書⽣·浦語2.0),由商湯科技和上海AI實驗室等單位聯合打造。
那麽新晉開源頂流Gemma,是在哪些細節上失分的呢?
在看完平均得分情況之後,我們繼續來看下細分賽道的情況。
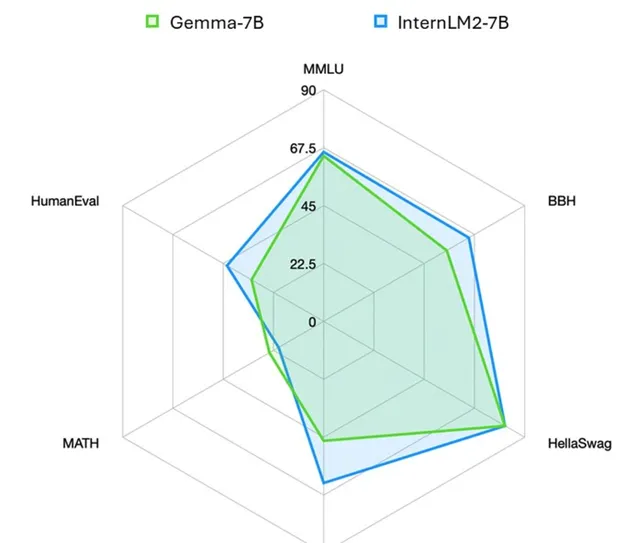
首先是在 綜合能力 (General)上,InternLM2-7B的得分為65.8分,略高於Gemma-7B。
其次是在 推理能力 (Reasoning)的2個基準中上,InternLM2-7B拿到一勝一平的成績。
接下來是 數學能力 (Math),同樣是2個基準,InternLM2-7B在 GSM8K 評測基準中大幅超過 16 分。
最後是 編程能力 (Code),InternLM2-7B則是高出了整整10分。
若是將Llama-2 7B也放進來,那麽InternLM2-7B則是在各項做到了完勝。
不僅如此,即便是拿7B的InternLM2和更大體量的13B Llama-2做比較,在各項細分成績中依舊是完勝。
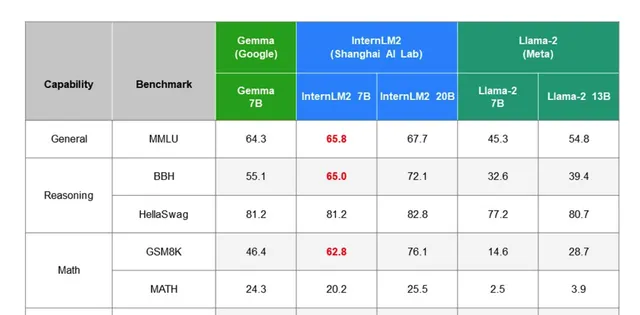
更直觀一些,InternLM2和Gemma之間的效能比較如下:
意外嗎?其實也並不意外。
因為國產開源大模型在Gemma釋出之前,就已經在各種榜單中站穩了一席之地,而且還不是曇花一現的那種。

例如InternLM2就是於今年1月17日「出道」,2種參數規格、3種模型版本,共計6個模型,全部免費可商用:
當時在與全球眾多7B量級選手的同台競技中,InternLM2便以「大圈包小圈」的姿勢在效能上取得了一定的優勢。
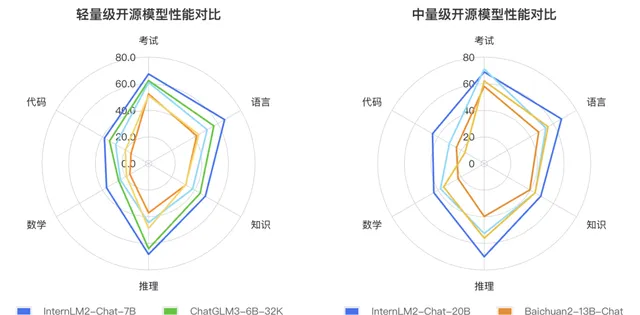
而且在與ChatGPT的比較過程中,在重點能力上,例如推理、數學、程式碼等方面是超越了ChatGPT的。
比如InternLM2-Chat-20B在MATH、GSM8K上,表現都超過ChatGPT;在配合程式碼直譯器的條件下,則能達到和GPT-4相仿水平。

InternLM2還支持200K超長上下文,可輕松讀200頁財報。200K文本全文範圍關鍵資訊召回準確率達95.62%。
例如在實際套用過程中,將長達3個小時的會議記錄、212頁長的財報內容「投餵」給它,InterLM2可以輕松hold住。

在不依靠小算盤等外部工具的情況下,可進行部份復雜數學題的運算和求解。
例如100以內數學運算上可做到接近100%準確率,1000以內達到80%準確率。
如果配合程式碼直譯器,20B模型已可以求解積分等大學級別數學題。
如何做到的呢?我們從研究團隊了解到,其所采取的策略關鍵並非是卷大模型的參數,而是在 數據 。
在團隊看來,提煉出一版非常好的數據後,它可以支持不同規格模型的訓練:
所以首先把很大一部份精力花在數據叠代上,讓數據在一個領先的水平。在中輕量級模型上叠代數據,可以讓我們走得更快。
團隊為此開發了一套先進的數據清洗和過濾系統,核心工作分為 三個關鍵部份 :
- 多維度數據價值分析 :該系統透過評估數據的語言品質和資訊密度等多個方面,對數據的價值進行全面分析和提升。例如,研究發現論壇網頁評論對模型效能的提升作用有限。
- 基於高品質語料的數據擴充套件 :團隊利用高品質語料的特性,從現實世界、網路資源和現有語料庫中收集更多相關數據,以進一步豐富數據集。
- 目標化數據補充 :透過有目的性地補充語料,特別是強化世界知識、數學邏輯和編程程式碼等領域的核心能力,以提升數據集的深度和廣度。
如此「三步走」的系統設計便讓數據集得到了相應的最佳化,讓它更加豐富、準確,並更好地支持模型的訓練和套用。
當然,InternLM2的開發不僅僅局限於提升模型的基礎效能,同時也緊跟當前的套用趨勢,對特定的下遊任務進行了效能增強。
例如,針對當前流行的超長上下文處理需求,團隊指出,在工具呼叫、數理推理等套用場景中,需要處理更長的上下文資訊。
為了應對這一挑戰,InternLM2透過擴大訓練視窗的容量和改進位置編碼技術,同時確保訓練數據的品質和結構化關系,成功地將上下文視窗的支持能力擴充套件到了20萬個tokens。
如此一來,不僅提高了模型處理長文本的能力,也最佳化了整體的訓練效率。
這便是InternLM2從「出道」至今,即便是面對頂流Gemma依舊能夠穩坐榜首的原因了。
結語
最後,回答一下文章最開始的那個問題——
Gemma給開源大模型到底帶來了什麽?
首先,是趨勢。
自從大模型的熱度起來之後,對於開源和閉源的話題也是一直在持續。
OpenAI的ChatGPT、GPT-4等,所代表的就是閉源大模型,其所具備的實力也是有目共睹;而此前Llama、Mitral等則是開源大模型的代表。
谷歌作為AI巨頭,在此前大模型巨頭混戰中是略顯疲態的,畢竟作為對標產品的Gemini,似乎也並未能撼動OpenAI的領先地位。
而此次谷歌罕見的開源了大模型、釋出Gemma,則是要以此來對標開源界的其它選手,並且從目前公布的成績來看,谷歌是取得了一定的優勢。
同時,從側面也反應出了,開源計畫在大模型的開發中有著重要的作用。
其次,是信心。
或許很多人對於大模型的發展依舊停留或關註於國外主流的科技巨頭。
但從各種榜單、評測的數據上來看,中國的大模型同樣也具備很強的競爭實力。
不僅僅是InternLM2-7B的開源模型,在不同參數體量的模型上,都有國產大模型選手在加入競爭。
而且從結果上,已然是做到了中文和英文整體能力上的全面超越。
從這一點上來看,Gemma的釋出不僅是在開源大模型界新添強勢玩家這麽簡單,更是給中國開源大模型,甚至整個AI大模型行業都帶來了一份信心。
總而言之,從開年到現在短短2個月的時間,我們能夠非常直觀感受到的一點便是大模型的戰場是越發的熱鬧。
不論是國內國外、開源閉源,亦或是各種多模態,從Gemini到Gemma,從Sora到Stable Diffusion 3,各大科技廠商你追我趕的態勢愈演愈烈。
但有一點是較為明確的,那就是所有釋出都在趨向於推理,趨向於如何把技術用起來。
因此,或許大模型在接下來的行程中,誰能讓自家的產品 「快好省」 地用起來,誰就能笑到最後。
— 完 —
量子位 QbitAI · 頭條號簽約
關註我們,第一時間獲知前沿科技動態











