汉藏语系,是世界第二大语系,也是一个相对独特的语系:汉藏语系呈现明显的汉-藏缅二分格局,其类型学之丰富度是其它语系中不曾见到的;大多数汉藏语都有先后演化出来的形态和词缀,在语法上明显靠近东南亚语言,一个半音节加显著的前缀-中缀偏好;汉藏语人群在基因上面也接近东南亚语言使用人群,尤其是南亚语和苗瑶语人群。
但是汉藏语系的基本词汇来源却很少与南方诸语言有关联,反而和分布于北欧-西伯利亚的乌拉尔语系关系密切,这在周围的东亚语言当中都找不到类似案例。
那么,什么导致了汉藏语系出现「词汇乌拉尔,语法东南亚」的独特现象呢?
目前笔者猜想该现象出现的原因和2万多年前曾在黄河中下游驻留的N父系单倍群以及人群迁移有关系,而且这个现象的产生还有某一人群学了另一人群语言的原因。
神秘莫测的Y-N单倍群:粟作文化创始者,部分下游支系(主要是N1a-M128)被汉藏专属O-M134击败北上
汉藏语系在形成之前,被认为和汉藏语系相关的人群——O2-M122、N-M231等人群很早就开始在我国中原地区扎根。
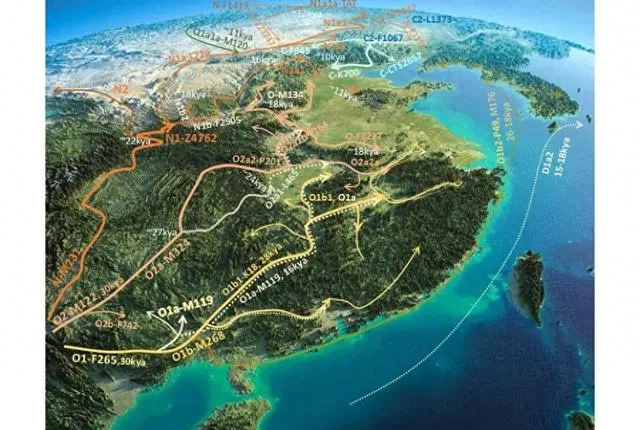
古代NO系人群迁移的路线,图源来自知乎用户@老犀牛。
在距离当今的三万多年前,中原大地上曾经有三批人群迁入,其中O1人群沿着东南沿海地区北上,O2则沿川渝地区北上,N-M231则是沿着原来的藏缅走廊北上:
O1-F265是第一批迁入中原大地的先民,约在32690年前迁入中原。而O2-M122在29460年前迁入中原,最年轻的N-M231则在23530年前迁入中原。——知乎用户拓扑维度
和汉藏语系高度相关的N-M1819,就是Y-N-M231的下游。
而在32000多年前的以O1a-M119占主体的南岛群体和O1b-M268这两支最开始居住在东亚的人群并没有感觉到异常情况,仍然很安逸的生活在黄淮海平原以及中原地区。
随后,和Y-O1人群分化近三万年的O2-M122从川渝地区北上N-M231,逐渐从江淮北上,击败并驱散了原有的Y-O1单倍群,使得原先的O1单倍群逐渐迁徙到大陆南方、台湾岛,甚至还有一部分往太平洋上移动。
至于另一部分没有来得及迁徙的父系单倍群为O1的前南岛和前南亚人群则融入前汉藏语的人群,塑造了汉藏语的底层,并在接触的过程中加强了底层的影响:喜欢使用前缀和中缀,重音节靠后;部分汉藏语如景颇语、珞巴语、嘉绒语都是典型的一个半音节语言。
N-M231在前往中原地区以及黄河以北后,创立了粟作文化,而汉藏语系人群的粟作文化可能就和这群人有关。

粟作文化人群的作物:小米,图源来自百度用户@蝌蚪五线谱。
而在N-M231创建粟作文化前的6000多年前,O2a-M122就已经在中原地区生活了。俗话说得好:近水楼台先得月。自然在中原地区的O2a-M 122是最先接触到粟作文化并发扬光大的一群人。
在接触粟作文化的过程中,O2-M122学习种植小米之后逐渐壮大。
之后在19000多年前的中国大陆,N1a-F1206因为打不过兴起的O2a-M122迁移到北亚,N1b-F2480和少量的N1a人群融入O2-M122。
然后又过了近一万年,汉藏语系诞生。
在汉藏语系诞生前,O2a-M122人群有大概率将N-M231的语言和词汇学走了。
也就是说,汉藏语系的诞生,其实是多个单倍群融入而导致的结果,其中被击败的单倍群有部分成了汉藏的语言文化底层,而且其中的N-M231以及N1a等单倍群还可能构成了奠基者效应,这个过程是很难说清的。
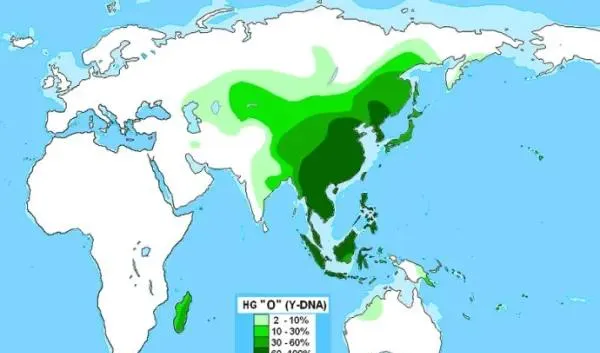
Y-O人群的分布。
也许在这一段史前的时间段内,汉藏人群和迁移没多远的乌拉尔人群有长时间的交流和接触,包括但不限于物质方面的接触和文化方面的接触,因此在汉藏语系诞生之前就已经涌入了大量乌拉尔语系词汇,并成了汉藏语的底层。
汉藏语系单有的N1b单倍群,在乌拉尔语系人群当中也存在,然而N1a和N1b实际上分化超过2万年,未必站得住脚
虽然说N1b是汉藏语人群的重要基因之一,但并不代表N1b基因仅仅在汉藏语人群中有分布。
N1b父系单倍群除了在黄河流域有所分布以外,在北极附近的涅涅茨地区也有所分布。
也就是说:N1b虽然是N南支,但仍然有可能使用乌拉尔语。
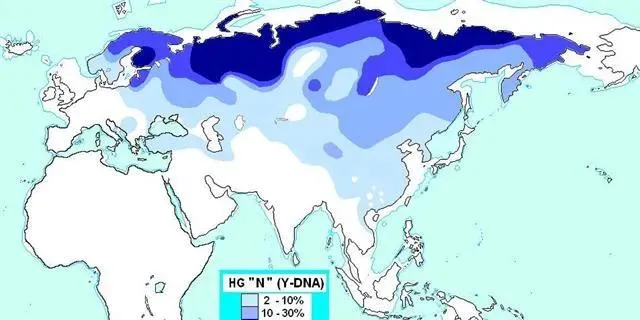
Y-N的分布。
因此分子人类学上来讲,似乎也支持汉藏语和乌拉尔语共祖。
然而,我们需要清楚的是,N1b和N1a之间分化已接近2万年,就算分子人类学上支持汉藏和乌拉尔共祖,在语言学上几乎也站不住脚了。
那只能说明:Y染色体为N1b的人群可能在某一时间点学习了乌拉尔语并根据自身语言特点进行了演变和改造。
语言未必会跟随基因,分子人类学无法完全且准确的和语言进行对应。
另一方面能解释汉藏语系虽然东南亚语言的特征比较多,但词汇接近乌拉尔语的角度是:语言未必会和基因一一对应,无论是Y染色体也好还是常染色体也罢,都无法准确的与语言对应。
到目前为止,除了印欧语系与其父系单倍群R1a或R1b有高度对应之外,其余的语系基本上都是几群人混合产生的,有轻重不等的克里奥尔化倾向。
而且即使是同一个单倍群人群,说的语言也不一定亲近。
譬如南亚语系人群和苗瑶语系人群均共享O3a3b-M7单倍群(目前归并为O2a3b-M7),但是苗瑶语系和南亚语系偏偏就不同源,即使列举出来部分同源词几乎也不是规律演化来的。

苗瑶语系和南亚语系的共享单倍群,图源B站用户@Arounsausdei
相反,苗瑶语系和汉藏语相关的词汇反而更多,虽然说O2a-M117和O2a3b-M7分化的时间也很早。
类似的还有突厥语系,和乌拉尔语系共享N1a-F4205单倍群基因,但二者的关系同样疏远到不可靠。
而汉藏和乌拉尔则正好与上述所提及的这几个语言相反,在汉藏语里面的部分词汇与乌拉尔语的对应词汇是存在规律音变对应的,比如汉藏语系当中常常m开头的词汇,到乌拉尔语里面就会丢掉m,且乌拉尔语系语言当中的词汇,提前把韵尾丢失;汉藏语的送气音,可能来自于第一辅音和第二个送气辅音的结合。

另一个例子是土耳其人,虽然大多数人Y单倍群和希腊的J同源,且常染色体也和希腊人相近,但仍然使用突厥语。
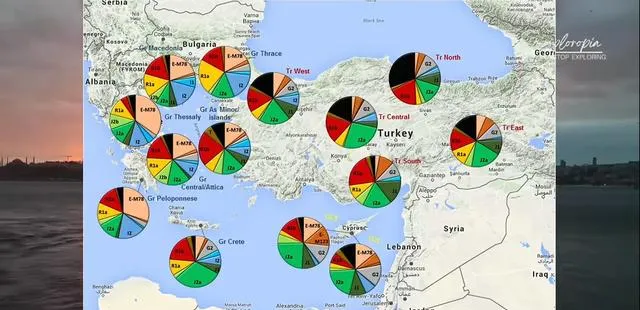
突厥人基因
还有一个例子是巴斯克人,虽然说Y单倍群、常染色体单倍群都和印欧人一模一样,但仍然保留了巴斯克语。
那么,这两个案例就可以解释汉藏语和乌拉尔语之间的关系了。
O2a-M122人群,有可能最开始既不讲汉藏语,也不说乌拉尔语,而是类似于南亚语和苗瑶语的一类语言。
但最后因为某种原因(粟作文化)而产生了文化或语言的认同,而改说了乌拉尔语,最后再根据自身语言的特点,而形成汉藏语。
因此,基于大多数语系的产生是多个Y单倍群人群混合导致的情况来看,语系和语系之间是否同源其一是内部影响(奠基者效应),其二则是某一民族改学了另一门语言。
结语
汉藏语系语法特征接近东南亚,词源接近乌拉尔语系确实是件很奇妙的事,原因复杂且多样,值得深入研究。
本人提出的只是关于基因和民族迁徙方面的,另一个角度其实可以从地理角度讨论,本篇就不再赘述了。











