Firefly:大模型训练工具, 4.2stars, 单卡微调7B
2024-03-31推荐
「Firefly」是一个专门针对大模型
训练
的开源框架,其主要功能包括对大模型进行
预训练、指令微调(SFT, Supervised Fine-Tuning)以及DPO
(可能指Direct Policy Optimization)等不同阶段的训练。以下是关于「Firefly」这个大模型微调平台的详细介绍:
项目概述
Firefly
是一个开源的大模型一站式训练框架,旨在简化和加速对多种大型语言模型进行训练和微调的过程。它支持对包括但不限于Gemma、Qwen1.5、MiniCPM、Mixtral-8x7B、Mistral、Llama等在内的主流大模型进行高效训练。该项目源代码可在GitHub上访问:
项目链接
: https://github.com/yangjianxin1/Firefly
关键特性与支持
多阶段训练支持
Firefly涵盖了大模型训练的三大核心阶段:
预训练
:利用超大规模文本数据对模型进行基础训练,任务通常是基于「下一个token预测」,需要处理数万亿级别的文本数据。
指令微调(SFT)
:使用含有明确指令的数据集,调整模型输出格式以与人类期望的对话模式对齐,赋予模型进行自然、有意义的聊天交互能力。
DPO(Direct Policy Optimization)
:一种基于人类反馈或偏好数据对模型进行价值观对齐训练的方法,目的是使模型输出更符合人类价值观和预期行为。相较于传统的RLHF(Reinforcement Learning with Human Feedback)方法中常用的PPO(Proximal Policy Optimization),DPO简化了流程,避免了奖励模型的构建,直接使用偏好数据训练,并减少了显存需求,仅需加载策略网络和参考网络。
灵活的训练技术
Firefly支持多种训练技术,以适应不同场景和资源限制:
全量参数训练
:对模型的所有参数进行更新,适用于拥有充足计算资源的情况。
LoRA (Low-Rank Adaptation)
:通过在模型的线性层添加低秩矩阵来实现轻量级微调,减少对模型参数的修改量,降低计算成本。
QLoRA (Quantized LoRA)
:可能是对LoRA技术的量化版本,进一步压缩模型参数,优化内存使用和计算效率。
硬件效率与优化
即使在有限的硬件资源下,Firefly也能有效地进行大模型训练:
单卡V100支持
:实验展示了使用单张NVIDIA V100 GPU即可完成对Qwen1.5-7B模型的SFT和DPO两阶段训练,表明Firefly能够有效利用单GPU进行大规模模型的微调。
QLoRA技术
:在所有Linear层应用QLoRA技术,通过添加adapter提升训练效果,同时可能有助于减少模型的内存占用。
实验案例与成果
Firefly团队对Qwen1.5-7B模型进行了SFT和DPO两阶段训练,并取得了显著的性能提升:
数据筛选与处理
:对训练数据进行了精细化筛选,确保输入高质量的数据进行微调。
训练参数
:提供了详细的训练参数配置,如学习率、批量大小、序列长度、优化器类型、学习率调度策略、LoRA相关超参数等,以供参考和复现实验。
模型性能
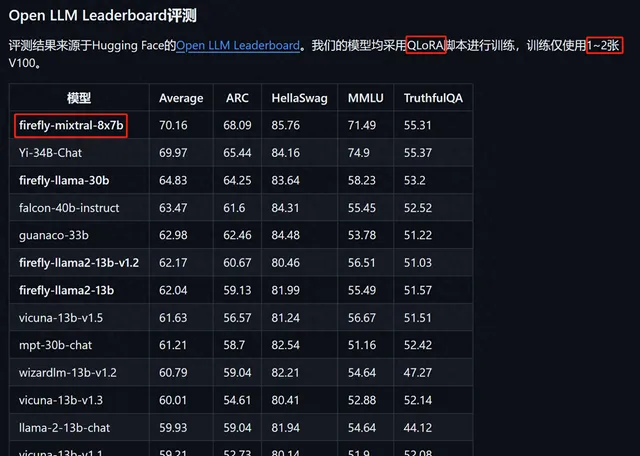
:经过Firefly训练后的Qwen1.5模型在Open LLM Leaderboard上的表现显著超越了原版Qwen1.5-7B-Chat和Gemma-7B-it等模型,平均得分提升近1分,显示出Firefly在微调大模型方面的强大能力。
Firefly微调后的模型
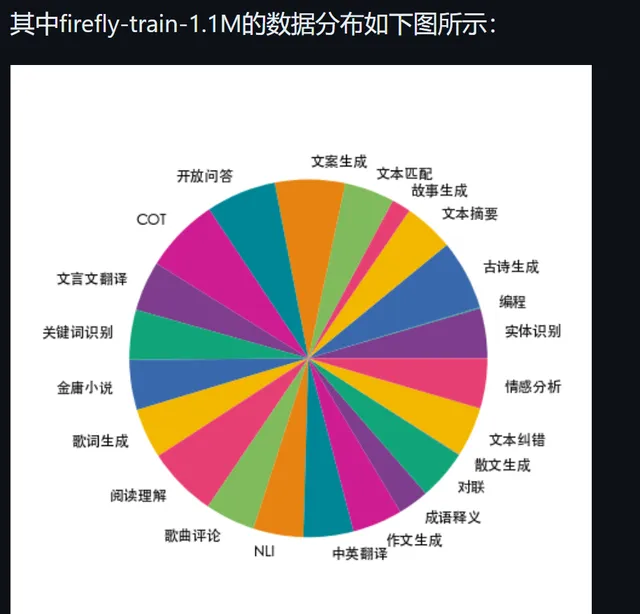
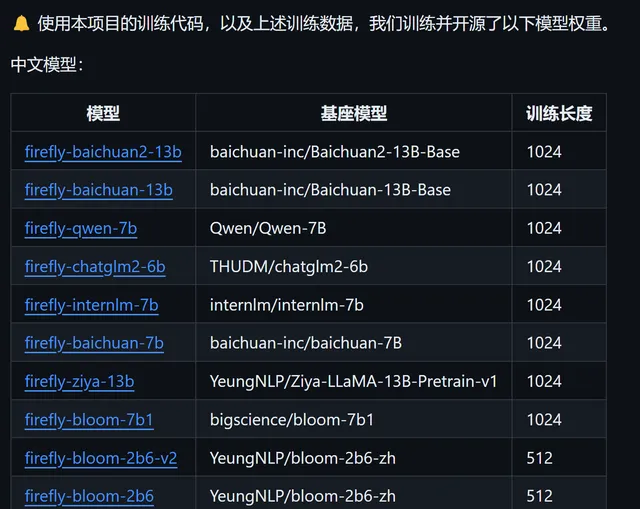
整理提供的指令微调数据
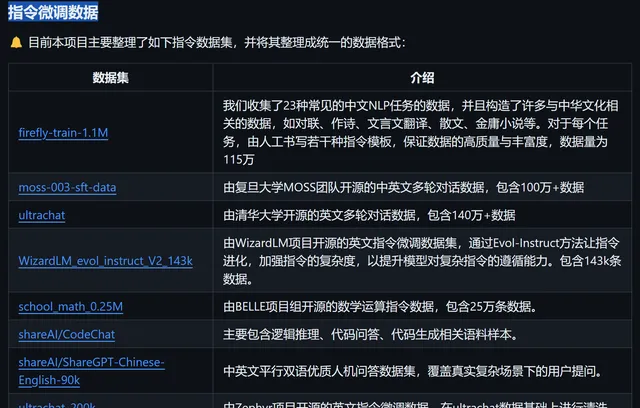
数据
综上所述,
Firefly
是一个专为大模型训练设计的开源框架,它集成了多种先进的训练技术和策略,支持预训练、指令微调(SFT)以及DPO等多种训练阶段,尤其擅长在有限的计算资源(如单张V100 GPU)上高效地微调大型语言模型,并已通过实验证明了其在提升模型性能方面的显著效果。无论是学术研究还是工业应用,Firefly都为用户提供了便捷、灵活且高效的大模型训练解决方案。