
链接:https://arxiv.org/abs/2304.08460
动机
指令调优使语言模型能够更有效地泛化,更好地遵循用户意图。不过,获取指令是十分昂贵且具有挑战性的。现有的方法采用诸如人工注释、众包数据集LLM生成噪声样例的方法。本文介绍了LongForm数据集,LongForm通过利用英语语料库的指令构建。本文提出从现有的语料库选择文档,并通过LLM基于文档生成指令。这种方法提供了一个更便宜、更干净的指令调优数据集。
本文在该数据集上微调T5,OPT和LLaMA模型,结果表明即使是较小的LongForm模型也具有良好的文本生成泛化能力。其无需对不同特定任务进行指令调整,便能取得比更大模型好的效果。
方法
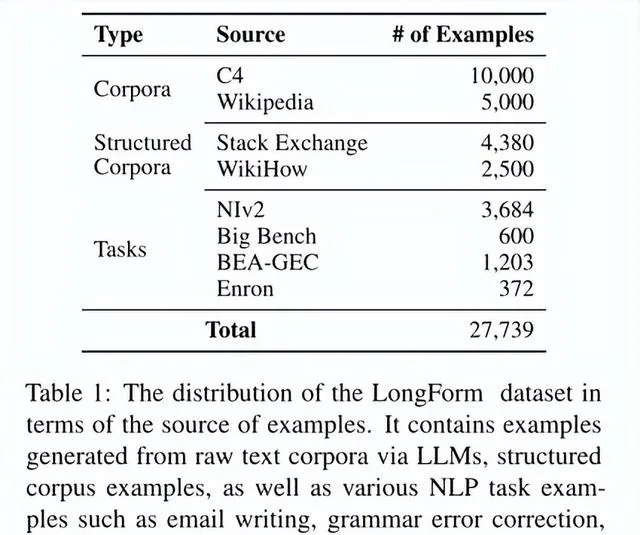
从语料库生成指令。本文从C4语料库中抽取了10000个样本,从英语维基百科中抽取了5000个样本。使用OpenAI的text-davinci-003模型作为LLM。设计了提示LLM针对一个给定的文档生成指令的prompt。本文创建了三个模板来使我们的指令风格多样化:正式指令风格、非正式聊天机器人风格和搜索引擎查询风格,概率分别为50%、30%和20%。

(1)本文提供了模板,在生成指令时加入长度限制信息。例如「以D句回应」或「以D词回应」,其中D表示目标文本的单词或句子的数量。
(2)本文同时也从结构化语料库不适用LLM直接收集数据作为语料库的扩展。
本文使用LLM生成指令,为了保证质量,采取了人工评估的方式。随机选取100个样本,要求人工判定指令是否与给定文档相关。实验发现100条指令中有97条是相关的。这种高度的相关性表明,与Self-Instruct数据集相比,将指令生成与语料库样例相结合可以潜在地提高用于指令生成的LLM的有效性。
实验与结果
本文使用LongForm数据集微调了T5-3B、OPT、LLaMA-7B模型,以评估instruction following文本生成的有效性。选择T0++、Tk-Instruct、Flan-T5、Alpaca-LLaMA-7B这三个指令微调模型和未经指令微调的OPT-30B作为baseline。
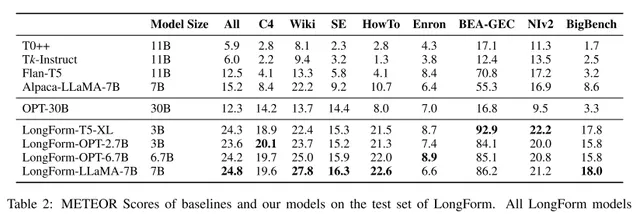
所有LongForm模型与之前的指令微调模型和原始LLM相比,都表现出明显的性能改进。3B参数的LongForm-T5-XL在所有子任务中的性能均优于具有11B参数的Flan-T5。
总结
本文中提出了名为LongForm的指令遵循长文本生成数据集,结合语料库的样例与LLM生成的指令、结构化语料库的实例。作者的评估表明,生成的指令与语料库高度相关,并包含了类型多样的任务。此外,本文证明了在LongForm数据集上进行指令微调的模型在各种指令长文本生成任务相较baseline具有很大的优势。











