Firefly:大模型訓練工具, 4.2stars, 單卡微調7B
2024-03-31推薦
「Firefly」是一個專門針對大模型
訓練
的開源框架,其主要功能包括對大模型進行
預訓練、指令微調(SFT, Supervised Fine-Tuning)以及DPO
(可能指Direct Policy Optimization)等不同階段的訓練。以下是關於「Firefly」這個大模型微調平台的詳細介紹:
專案概述
Firefly
是一個開源的大模型一站式訓練框架,旨在簡化和加速對多種大型語言模型進行訓練和微調的過程。它支持對包括但不限於Gemma、Qwen1.5、MiniCPM、Mixtral-8x7B、Mistral、Llama等在內的主流大模型進行高效訓練。該專案原始碼可在GitHub上存取:
專案連結
: https://github.com/yangjianxin1/Firefly
關鍵特性與支持
多階段訓練支持
Firefly涵蓋了大模型訓練的三大核心階段:
預訓練
:利用超大規模文本數據對模型進行基礎訓練,任務通常是基於「下一個token預測」,需要處理數萬億級別的文本數據。
指令微調(SFT)
:使用含有明確指令的數據集,調整模型輸出格式以與人類期望的對話模式對齊,賦予模型進行自然、有意義的聊天互動能力。
DPO(Direct Policy Optimization)
:一種基於人類反饋或偏好數據對模型進行價值觀對齊訓練的方法,目的是使模型輸出更符合人類價值觀和預期行為。相較於傳統的RLHF(Reinforcement Learning with Human Feedback)方法中常用的PPO(Proximal Policy Optimization),DPO簡化了流程,避免了獎勵模型的構建,直接使用偏好數據訓練,並減少了視訊記憶體需求,僅需載入策略網絡和參考網絡。
靈活的訓練技術
Firefly支持多種訓練技術,以適應不同場景和資源限制:
全量參數訓練
:對模型的所有參數進行更新,適用於擁有充足計算資源的情況。
LoRA (Low-Rank Adaptation)
:透過在模型的線性層添加低秩矩陣來實作輕量級微調,減少對模型參數的修改量,降低計算成本。
QLoRA (Quantized LoRA)
:可能是對LoRA技術的量化版本,進一步壓縮模型參數,最佳化記憶體使用和計算效率。
硬件效率與最佳化
即使在有限的硬件資源下,Firefly也能有效地進行大模型訓練:
單卡V100支持
:實驗展示了使用單張NVIDIA V100 GPU即可完成對Qwen1.5-7B模型的SFT和DPO兩階段訓練,表明Firefly能夠有效利用單GPU進行大規模模型的微調。
QLoRA技術
:在所有Linear層套用QLoRA技術,透過添加adapter提升訓練效果,同時可能有助於減少模型的記憶體占用。
實驗案例與成果
Firefly團隊對Qwen1.5-7B模型進行了SFT和DPO兩階段訓練,並取得了顯著的效能提升:
數據篩選與處理
:對訓練數據進行了精細化篩選,確保輸入高質素的數據進行微調。
訓練參數
:提供了詳細的訓練參數配置,如學習率、批次大小、序列長度、最佳化器類別、學習率排程策略、LoRA相關超參數等,以供參考和復現實驗。
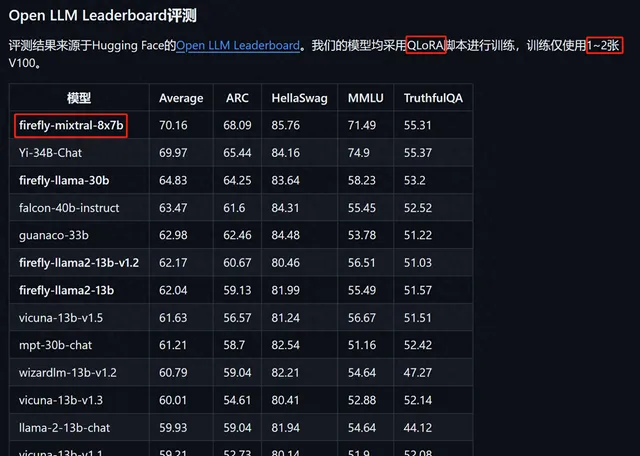
模型效能
:經過Firefly訓練後的Qwen1.5模型在Open LLM Leaderboard上的表現顯著超越了原版Qwen1.5-7B-Chat和Gemma-7B-it等模型,平均得分提升近1分,顯示出Firefly在微調大模型方面的強大能力。
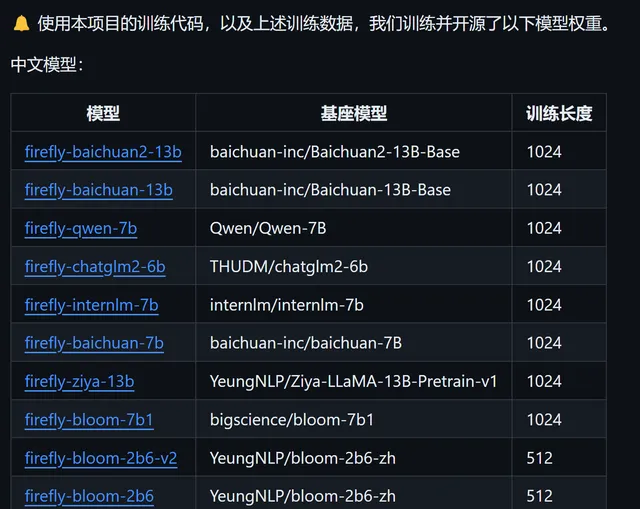
Firefly微調後的模型
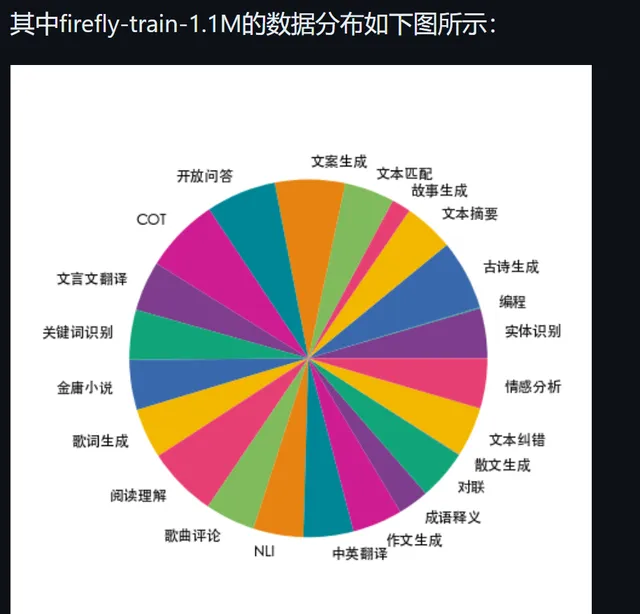
整理提供的指令微調數據
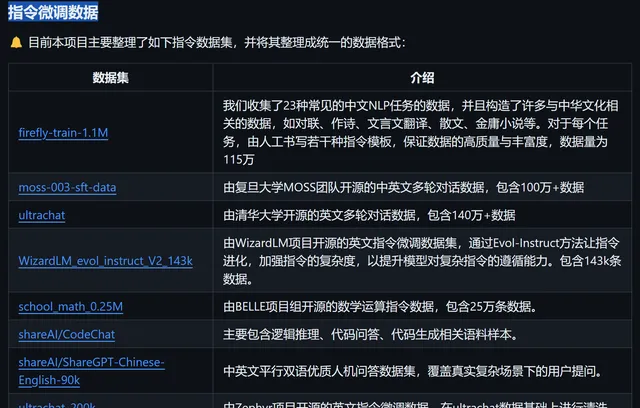
數據
綜上所述,
Firefly
是一個專為大模型訓練設計的開源框架,它整合了多種先進的訓練技術和策略,支持預訓練、指令微調(SFT)以及DPO等多種訓練階段,尤其擅長在有限的計算資源(如單張V100 GPU)上高效地微調大型語言模型,並已透過實驗證明了其在提升模型效能方面的顯著效果。無論是學術研究還是工業套用,Firefly都為使用者提供了便捷、靈活且高效的大模型訓練解決方案。