
雖然輝達(Nvidia)目前仍是AI芯片市場的霸主,不過年中開始,挑戰者AMD的最強AI芯片MI300X也即將大批次出貨,可能將會搶下部份輝達的市場,並再次影響從晶圓代工到伺服器的AI產品供應鏈。
根據日本瑞穗證券報告,在目前的AI芯片市場,輝達的市占率高達95%,「遠比AMD和英特爾的份額相加還要高」。輝達在2023年第四季,僅數據中心業務的營收就高達184億美元,較前一年同期增加了409%。
但隨著AMD的最強AI芯片MI300X的出貨,或將搶下輝達的部份市場份額。據業內人士透露,AMD MI300X芯片目前已小量出貨,微軟等正在測試。這款芯片下半年預計會有大量出貨,主要買家是微軟等有大型數據中心的公司,「5或6月開始,就會有一批拉貨潮。」
據悉,微軟、Meta、甲骨文、OpenAI等大廠都會采購這款芯片,美超威、華碩、技嘉、鴻佰科技、英業達、雲達等伺服器廠也在設計解決方案。在去年第三財季法說會,AMD CEO蘇姿豐表示,數據中心收入2024年可達20億美元,這代表MI300會是AMD史上最快營收達10億美元的產品。
AMD反擊輝達的武器,是利用更高容量的高頻寬內存(HBM)和先進封裝提高AI運算效率。AI芯片挑戰在於,要在內存和處理器間搬動大量數據,因此AMD采用台積電的先進封裝技術,將原本放在芯片外的內存直接搬進芯片,讓大量數據直接在芯片內就能從內存搬到處理器計算。
在此前的釋出會上,AMD CEO蘇姿豐就表示,只用一顆芯片,就能執行數據量高達40GB的AI模型。而這顆芯片最高可執行80GB 的AI模型。
根據官方公布的數據顯示,MI300X的HBM容量高達192GB,比輝達H100 SXM芯片的80GB高了一倍多,多項算力測試效能也高於輝達H100 SXM芯片。不過,隨後輝達也拿出數據來表示,輝達H100芯片效能比MI300X明顯更快,並公布測試細節,讓使用者自行比較兩顆芯片效能。雙方之間競爭的火藥味明顯上升。
對於AMD來說,除了MI300X的產品優勢之外,它還有著另一大優勢,那就是客戶不希望AI芯片市場被輝達獨占。
據業界人士觀察,「AI芯片問題不是產能不夠,是輝達賣的很貴。」微軟等大客戶不希望市場只有一家供應商很正常,但自研芯片又無法像專業的半導體公司,在效能上保持領先,自然希望有新的供應商出現,不僅效能能和輝達匹敵,價格還更具優勢。
根據富國銀行此前的預測,AMD雖然在2023年的AI芯片的營收僅為4.61億美元,但是2024年將有望增長到21億美元,將有望拿到4.2%的市場份額。英特爾也可能拿到將近2%的市場份額。這將導致輝達的市場份額可能將小幅下滑到94%。
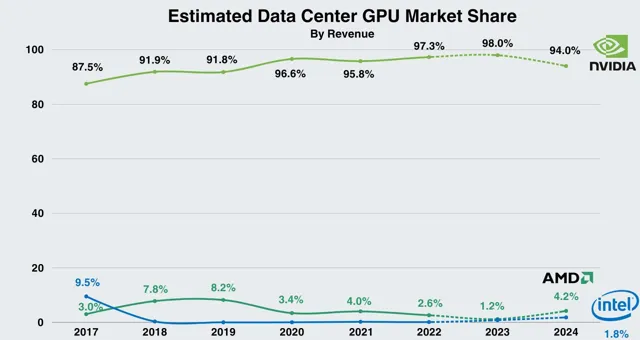
不過,根據AMD CEO蘇姿豐在1月30日的電話會議上公布的數據顯示,AMD在2023年四季度的AI芯片營收已經超越此前預測的4億美元,同時2024年AMD的AI芯片營收預計也將達到35億美元,高於先前預測的20億美元。如果,AMD的預測數據準確的話,那麽其2024年在AI芯片市場的份額有望進一步提高到7%左右。
然而輝達也不會坐等競爭對手壯大。3月18日,輝達即將召開GTC2024大會,屆時將會正式釋出全新的AI芯片H200,將會把HMB記憶體從上一代的80GB提升至141GB,並且采用的是速率更快的HBM3E規格。此外,輝達今年還將提出更強的B100芯片,其效能將會達到H200的兩倍。AMD明年也會推出新一代的采用HBM3E記憶體的AI芯片MI350進行應對。
供應鏈方面,隨著輝達和AMD對於HBM容量及規格的需求提升,HBM的供應也將持續供不應求。目前兩大HBM供應商——SK海力士和美光的今年的HBM產能都已經銷售一空。
與此同時,台積電的先進封裝產能也仍面臨供應緊張的局面,因為不僅AI芯片需要先進封裝產能,HBM芯片的制造也需要先進封裝產能。對此,台積電在2023年啟動了其CoWoS先進封裝產能大擴產計劃。近日業內傳出,台積電本月對台系器材廠再度追單,交機時間預計將在今年第四季,因此,今年年底台積電CoWoS月產能將有機會比其原定的倍增目標的3.5萬片進一步提高到4萬片以上。台積電更是和SK海力士結盟,大力布局HBM。
業界人士預測,接下來AI芯片會越來越多元,從高階一路到中低階,配合從模型訓練到AI邊緣計算需求。
比如,上個月美國人工智能初創公司Groq最新推出的面向雲端大模型的推理芯片引發了業內的廣泛關註,該芯片采用了全新的Tensor Streaming Architecture (TSA) 架構,以及擁有超高頻寬的SRAM,從而使得其對於大模型的推理速度提高了10倍以上,甚至超越了輝達的GPU。這也使得一些客戶對於Groq的AI芯片產生的興趣。
近日,新創AI芯片公司Cerebras Systems近日推出了其第三代的晶圓級AI芯片WSE-3,具有125 FP16 PetaFLOPS的峰值效能,相比上一代的WSE-2提升了1倍,將用於訓練業內一些最大的人工智能模型。與此同時,Cerebras還推出了基於WSE-3的CS-3超級電腦,可用於訓練參數高達24萬億的人工智能模型,這比相比基於WSE-2和其他現代人工智能處理器的超級電腦有了重大飛躍。
「如果只是用來推理,X86和Arm處理器也有機會。」
編輯:芯智訊-浪客劍











