SignVTCL: Multi-Modal Continuous Sign Language Recognition Enhanced by Visual-Textual Contrastive Learning
標題 : SignVTCL:透過視覺文本對比學習增強的多模態連續手語辨識
地址 : https://arxiv.org/pdf/2401.11847.pdf
摘要 : 手語辨識(SLR)在促進聽力受損社群的交流中發揮著至關重要的作用。SLR是一項弱監督任務,整個視訊都用手語詞匯進行註釋,這使得在視訊片段中辨識相應的手語詞匯變得具有挑戰性。最近的研究表明,SLR的主要瓶頸是由於大規模數據集的有限可用性而導致的訓練不足。為了解決這一挑戰,我們提出了SignVTCL,這是一個透過視覺文本對比學習增強的多模態連續手語辨識框架,充分利用了多模態數據和語言模型的泛化能力。SignVTCL同時整合了多模態數據(視訊、關鍵點和光流)來訓練統一的視覺骨幹,從而產生更強大的視覺表示。此外,SignVTCL包含了一種視覺文本對齊方法,包括詞匯級和句子級對齊,以確保在個別手語詞匯和句子級別上實作視覺特征和手語詞匯的精確對應。在三個數據集(Phoenix-2014、Phoenix-2014T和CSLDaily)上進行的實驗證明,與先前方法相比,SignVTCL取得了最先進的結果。
解決的問題 :
該論文要解決的問題是提高手語辨識框架的效能,透過結合視覺和文本對比學習,充分利用多模態數據的潛力和語言模型的泛化能力。具體來說,該論文提出了一個名為SignVTCL的框架,該框架能夠同時整合視訊、關鍵點和光學流等多種模態數據,訓練出一個統一的視覺主幹網路,從而產生更穩健的視覺表示。同時,該框架還關註了句子級別的對齊問題,旨在將視覺特征和文本特征在句子級別上進行整合和校準,以便更全面地理解句子中包含的語意和上下文資訊。透過這種方式,該框架旨在提高手語辨識的準確性和魯棒性,從而為聾啞人群提供更好的交流和理解服務。
解決的方法 :
該論文解決的方法主要是利用多模態數據,包括視訊、文本和關鍵點序列,來理解和辨識手語。
首先,該方法從視訊中提取關鍵點,並將每個提取的關鍵點視為獨立的通道輸入到模型中。這些關鍵點序列可以用作表示手的形狀和位置,從而提供有關手語動作的重要資訊。
其次,該方法利用光學流來捕捉手語動作的微妙細節,這有助於更準確地辨識手語。光學流提供了一種密集的運動表示,使得模型能夠更好地理解手語動作。
最後,該方法使用深度網路架構RAFT來提取高品質的光學流資訊。RAFT被設計用於提取光學流,可以熟練地從視訊數據中獲取相關資訊。提取的光學流資訊被儲存為一系列影像,這樣就可以將光學流資訊表示為類似於視訊數據的形式。
為了有效地從這三種模態中學習視覺表示,該方法構建了一個包含三個分支的網路。每個分支由S3D網路的頭四個塊組成,這是一種常用於視訊理解任務的的三維摺積網路架構。在關鍵點分支中,第一個塊的第一個摺積層被替換以適應關鍵點的輸入格式。每個分支將輸入數據處理成幀級別的特征f {v,k,o} = {f {v,k,o}}t T/4t=1 ∈ RT/4×dv,然後將這些特征單獨饋送到我們頭網路中的不同時間頭中,其中dv是視覺隱藏維度。
透過這種方法,該論文成功地利用多模態數據來理解和辨識手語,從而為手語辨識領域的發展做出了貢獻。
創新點 :
提出了SignVTCL框架,透過多模態連續的手勢語言辨識,有效地利用了多模態數據和語言模型的泛化能力。同時,SignVTCL整合了視訊、關鍵點和光學流等多模態數據,訓練出一個統一的視覺主幹網路,從而產生了更穩健的視覺表示。
在SignVTCL中,論文引入了一種視覺-文本對齊方法,將詞級別和句子級別的對齊結合起來,確保了視覺特征與註釋之間在單個詞和句子層面上的精確對應。此外,為了最佳化視覺和預訓練文本知識的保留,論文還提出了特征介面卡,透過凍結預訓練的文本編碼器並將其用作教師模型來進行監督學習。
系統架構 :
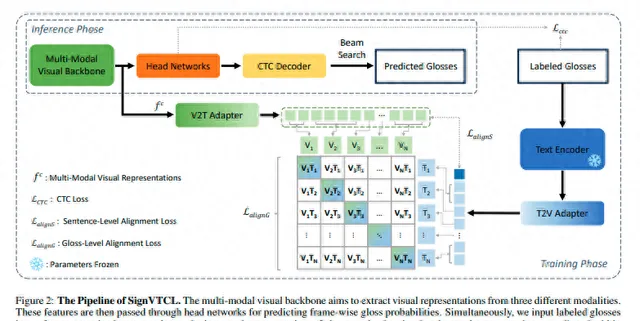
結果 :

結論 :
在這篇論文中,我們提出了SignVTCL,這是一個多模態連續手語辨識框架,整合了視訊、關鍵點和光流等多種模態,共同學習視覺表示。透過結合這些模態,SignVTCL捕捉了手語中復雜的手部運動和動態的身體部位運動,增強了模型對手語的理解並提高了辨識能力。此外,我們引入了一種視覺文本對齊方法,該方法在詞匯和句子兩個層面上對齊視覺和文本特征嵌入,從而在視覺符號和文本上下文之間建立了有意義且精確的對應關系,提高了SLR的效能。在多個數據集上進行的廣泛實驗證明了我們的SignVTCL在取得最先進效能方面的有效性。我們期望所提出的SignVTCL可以激發其他工作探索在視訊理解任務中的多模態學習和對比學習。
實際套用價值 :
- 多模態資訊融合:論文提出了一種多模態資訊融合的方法,透過將視訊、關鍵點、光學流和文本資訊進行聯合處理,可以更全面地理解視訊內容,為視訊分析、理解、摘要生成等任務提供了新的思路和方法。
- 跨模態特征對齊:透過使用Video-to-Text和Text-to-Video介面卡,該論文實作了視覺和文本特征之間的對齊。這有助於解決諸如視訊描述生成、視覺問答等跨模態任務,使得電腦可以更好地理解和處理多模態資訊。
- 模型可延伸性:該論文提出的方法可以方便地擴充套件到更大的數據集和任務中,有助於提高模型的效能和泛化能力。
- 套用場景廣泛:該論文提出的方法可以套用於各種場景,如視訊摘要、視訊描述生成、視覺問答、行為辨識等,具有廣泛的套用前景。
- 可解釋性強:該論文的方法透過使用CTC損失函式和Temporal Linear Layer等結構,使得模型具有較好的可解釋性,有助於理解模型的工作原理和改進模型的設計。











