進入AI大模型時代,單個GPU訓練AI模型早已成為歷史。 如何讓成百上千個GPU互連,組成宛若一個GPU的超級計算系統,成為業界熱點!
NVIDIA DGX SuperPOD是下一代數據中心人工智慧(AI)架構。旨在提供AI模型訓練、推理、高效能計算(HPC)和混合套用中的高級計算挑戰所需的計算效能水平,以提高預測效能和解決方案的時間。
下面一起學習輝達p00→Gp00→GB200三代產品的GPU互連架構方案。
1、基於p00搭建256 GPU的SuperPod
在DGX A100情況下,每個節點上8張GPU透過NVLink和NVSwitch互聯,機間(不同伺服器)直接用200Gbps IB HDR網路互聯(註:機間網路可以用IB網路,也可以用RoCE網路)。
而在DGX p00的情況下,輝達把機內的NVLink擴充套件到機間,增加了NVLink-network Switch,由NVSwitch負責機內的交換,NVLink-network Switch則是負責機間交換的交換機,基於NVSwitch和NVLink-network Switch可以搭建256個p00 GPU組成的SuperPod(即一個超級計算系統 ),256個GPU卡Reduce頻寬仍然可以打到450 GB/s,和單機內部8個GPU卡的Reduce頻寬完全一致。
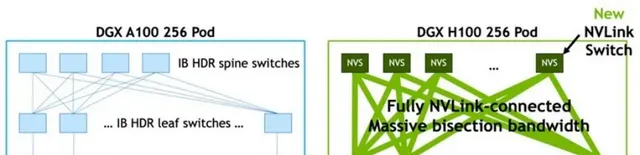
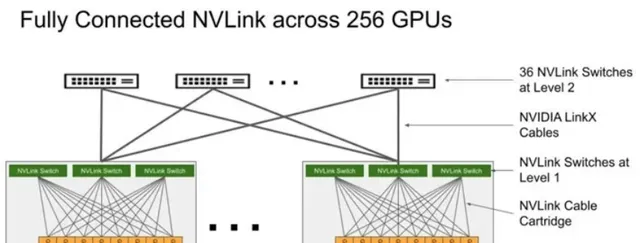
但是DGX p00的SuperPod也存在一定的問題,跨DGX p00節點的連線只有72個NVLink連線,SuperPod系統裏並不是無收斂的網路。
如下圖,在DGX p00系統裏,四個NVSwitch留出了72個NVLink連線用於透過NVLink-network Switch連線到其他DGX p00系統,72個NVLink連線的總雙向頻寬是3.6TB/s,而8個p00的總雙向頻寬是7.2TB/s,因此,在SuperPod系統裏在NVSwitch處存在收斂。
圖:基於p00搭建256 GPU的SuperPod
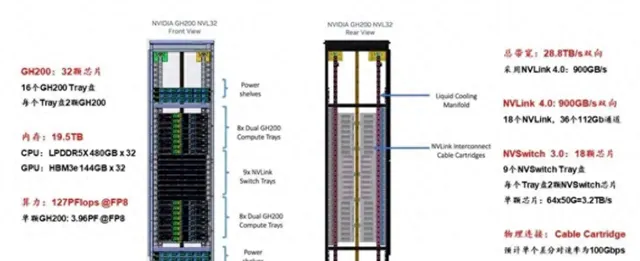
2、基於Gp00和Gp00 NVL32搭建256 GPU的SuperPod
2023年,輝達宣布生成式AI引擎DGX Gp00投入量產,Gp00是p00 GPU(p00與p00主要是記憶體大小和頻寬效能方面的區別)與Grace CPU的結合體,一個Grace CPU對應一個p00 GPU,Gp00除了GPU之間采用NVLink4.0連線以外,GPU和CPU之間也采用NVLink4.0連線。
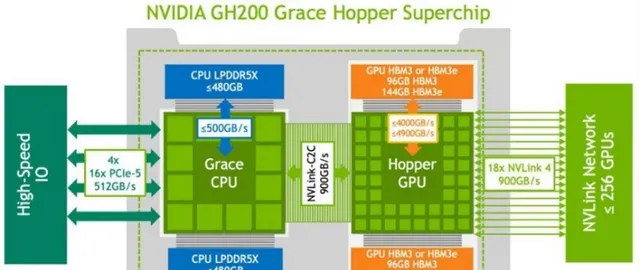
Gp00透過NVLink 4.0的900GB/s超大網路頻寬能力來提升算力,伺服器內部可能采用銅線方案,但伺服器之間可能采用光纖連線。對於單個256 Gp00芯片的集群,計算側1個Gp00對應9個800Gbps(每個800Gbps對應100GB/s,2條NVLink 4.0鏈路)光模組。
Gp00 SuperPod與DGX p00 SuperPod的區別在於在單節點內部和節點之間互聯時都是用NVLink-network Switch互聯。
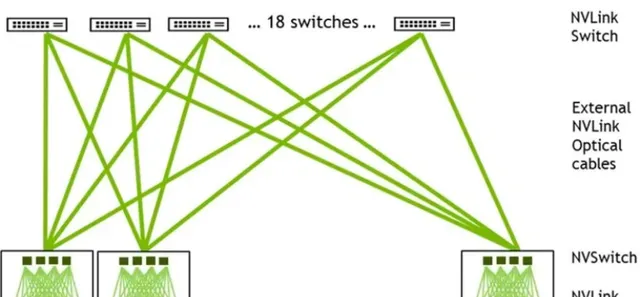
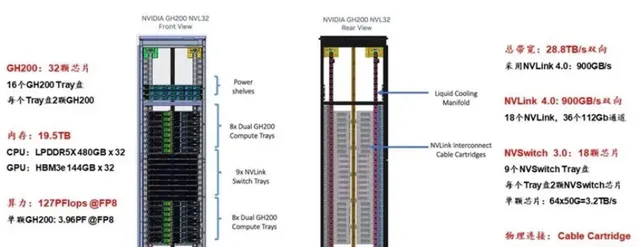
DGX Gp00采用二級Fat-tree結構,由8個Gp00和3個一級NVLink-network Switch(每個NVSwitch Tray包含2個NVSwitch芯片,有128個Port)組成單機,32個單機經由36個二級NVLink-network Switch全互聯,形成了256個Gp00的SuperPod(註意是36個二級NVLink-network Switch,這樣才能保證無收斂)。
圖:基於Gp00搭建256 GPU的SuperPod
Gp00 NVL32為機架級集群,單個Gp00 NVL32擁有32個Gp00 GPU和9個NVSwitch Tray(18個NVSwitcp.0芯片),如果組成256個GPU的Gp00 NVL32超級節點,則需要再配置一級機間的36個NVLink-network Switch即可。
3、基於GB200 NVL72搭建576 GPU的SuperPod
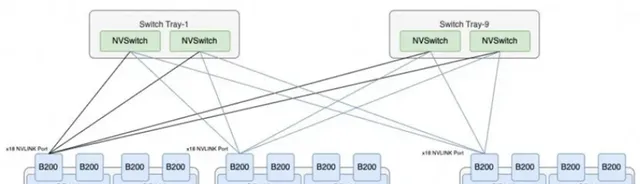
和Gp00不同,一個GB200由1個Grace CPU和2個Blackwell GPU組成(註:單個GPU算力不完全等價B200)。GB200 Compute Tray是基於輝達MGX設計的,一個Compute Tray包含2個GB200,也就是2個Grace CPU、4個GPU。
一個GB200 NVL72節點包含18個GB200 Compute Tray,即36個Grace CPU,72個GPU,此外還包含9個NVLink-network Switch Tray(每個Blackwell GPU有18個NVLink,而每個第4代NVLink-network Switch Tray包含144個NVLink Port,所以需要72*18/144=9個NVLink-network Switch Tray實作全互聯)。
圖:GB200 NVL72內部拓撲架構
在輝達的官方宣傳中,8個GB200 NVL72組成一個SuperPod,從而組成一個由576個GPU組成的超級節點。
但是,我們透過分析可以看出GB200 NVL72機櫃中的9個NVLink-network Switch Tray已經全部用於連線72個GB200了,已經沒有額外的NVLink介面用於擴充套件構成更大規模的兩層交換集群了,576個GPU的SuperPod從輝達官方的圖片來看,更多的是透過Scale-Out RDMA網路互聯的,而並不是透過Scale-Up的NVLink網路互聯的。如果需要透過NVLink互聯來支持576個GPU的SuperPod,則需要每72個GB200配置18個NVSwitch,這樣單機櫃就放不下了。
另外,輝達官方說NVL72有單機櫃版本,也有雙機櫃的版本,並且雙機櫃每個Compute Tray只有一個GB200子系統,這樣有可能是透過雙機櫃的版本來實作透過NVLink互聯來支持576個GPU的SuperPod,這樣這個雙機櫃版本的每個雙機櫃有72個GB200和18個NVLink-network Switch Tray,從而可以滿足兩層集群的部署需要。如下圖所示:
圖:基於GB200搭建576GPU的SuperPod
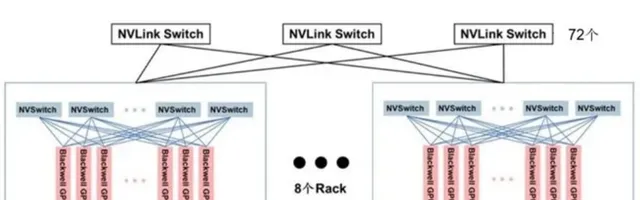
和上一代256個p00全互聯類似結構類似,只是第一級及第二級所有的裝置台數有所不同,需要兩級NVLink-network Switch互聯:
第一級的一半Port連線576個Blackwell GPU,所以需要576*18/(144/2) =144個NVLink-network Switch,每個NVL72有18個NVLink-network Switch Tray。第二級Port全部與第一級的NVLink-network Switch Port連線,所以需要144*72/144=72 個NVSwitch。
文章來源:可鑒智庫











