點選藍字
關註我們
關註並星標
從此不迷路
電腦視覺研究院
公眾號ID | 電腦視覺研究院
學習群 | 掃碼在主頁獲取加入方式
電腦視覺研究院專欄
Column of Computer Vision Institute
今天我們詳細分析優圖的「 分布式知識蒸餾損失 」套用在人臉辨識領域,去較大程度改善了困難樣本的技術,希望持續關註我們「 電腦視覺研究院 」!
1、前文摘要
今天我們「 電腦視覺研究院 」深入解讀優圖的「 分布式知識蒸餾損失改善人臉辨識困難樣本 」技術。上一期我們也詳細分享了什麽是「知識蒸餾」技術!(連結:騰訊優圖 | 分布式知識蒸餾損失改善困難樣本 )
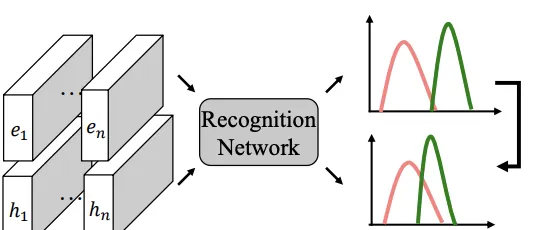
目前基於深度學習的人臉辨識演算法已經可以較好的處理簡單樣本,但對於困難樣本(低分辨率、大姿態等)仍表現不佳。目前主要有兩種方式嘗試解決這一問題。 第一種方法: 充分利用某種需要處理的人臉畸變的先驗資訊,設計特定的結構或損失函式。這種方式通常不能方便地遷移到其他畸變型別。 第二種方法: 透過設計合適的損失函式,減小類內距離,增大類間距離,得到更具辨別能力的人臉特征。這種方式一般在簡單和困難樣本上存在明顯的效能差異。
為了提升人臉辨識模型在困難樣本上的效能,提出了一種基於分布蒸餾的損失函式。 具體來說,首先透過一個預訓練的辨識模型構造兩種相似度分布(從簡單樣本構造的Teacher分布和從困難樣本的Student分布),然後透過分布蒸餾損失函式使Student分布靠近Teacher分布,從而減小Student分布中的同人樣本和非同人樣本的相似度重合區域,提高困難樣本的辨識效能。
最後作者在常用的大規模人臉測試集和多個包含不同畸變型別(人種、分辨率、姿態)的人臉測試集上進行了充分的實驗,驗證了方法的有效性。
2、背景
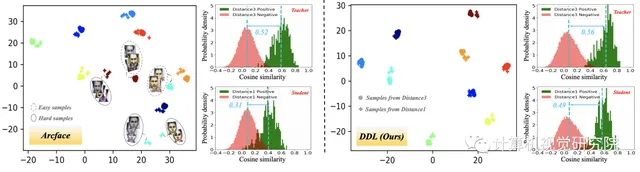
大規模人臉辨識在無約束影像上的一個主要挑戰是處理姿態、分辨率和光照等方面的不同變化。雖然有些變化很容易解決,但許多其他變化相對困難。如下圖所示。
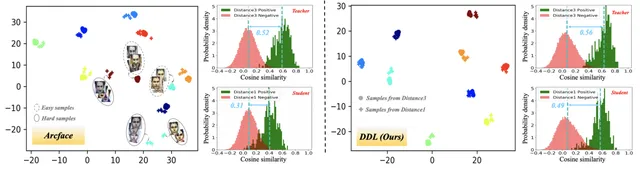
State-of-the-Art (SotA) 像Arcface這樣的面部份類器很好地處理特征空間中具有緊密分組的小變化的影像。作者把這些表示為簡單的樣本。相反,具有較大變化的影像通常遠離特征空間中的簡單影像,並且更難處理。作者把這些表示為難樣品。為了更好地辨識這些難樣本,通常有兩種方案:variation-specific和generic方法。
variation-specific 方法通常是為特定的任務設計的。例如,為了實作姿態不變的人臉辨識,提取手工制作或學習的特征,以增強對姿態的魯棒性,同時保持對身份的鑒別性。為了解決分辨率不變人臉辨識問題,在繪制低分辨率(LR)和高分辨率(HR)影像的[ Shekhar, S., Patel, V.M., Chellappa, R.: Synthesis-based recognition of low resolution faces. In: IJCB. pp. 1–6. IEEE ]中,學習了一個統一的特征空間。這些工作[ Zhang, K., Zhang, Z., Cheng, C.W., Hsu, W.H., Qiao, Y., Liu, W., Zhang, T.: Super-identity convolutional neural network for face hallucination. In: ECCV. pp. 183–198 (2018) ]首先在LR影像上套用超分辨率,然後對超分辨影像進行辨識。然而,上述方法是專門為各自的變化而設計的,因此它們從一個變化推廣到另一個變化的能力是有限的。然而,處理現實世界辨識系統中的多種變化是非常可取的。
與variation-specific 方法不同,generic 方法側重於提高小類內距離和大類間距離的面部特征的鑒別能力。基本上,先前的工作分為兩類,即基於Softmax損失的方法和基於三重態損失的方法。基於Softmax損失的方法將每個標識視為一個唯一的類來訓練分類網路。由於傳統的Softmax損失不足以獲得判別特征,因此提出了幾種提高判別能力的變體[ Deng, J., Guo, J., Xue, N., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: CVPR. pp. 4690–4699 (2019) ]。相反,基於三重態損失的方法[ Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: A unified embedding for face recognition and clustering. In: CVPR. pp. 815–823 ]直接學習每張臉的歐幾瑞德空間嵌入,其中來自同一個人的臉與其他人的臉形成一個單獨的集群。透過大規模的訓練數據和精心設計的網路結構,這兩種方法都能獲得不錯的結果。

然而,這些方法的效能在難樣品上急劇下降,如非常大的姿態和低分辨率的面。Arcface的強人臉分類器從HR影像中提取的特征分離得很好,但從LR影像中提取的特征不能很好地區分。從正對和負對的角度分布,我們可以很容易地觀察到Arcface在LR人臉影像上存在更多的混淆區域。因此,這種通用方法在難樣本上的效能更差是一個自然的結果。

為了縮小簡單樣品和難樣品之間的效能差距,作者提出了一種新的分布蒸餾損失(DDL)。 透過利用variation-specific 和generic 方法中的最佳方法,新提出的方法是通用的,可以套用於不同的變異,以提高難樣本中的人臉辨識。
具體來說,首先采用當前的SotA人臉分類器作為基線(例如ArcFace)來構造教師之間的初始相似性分布(例如,下圖中d3的簡單樣本)和學生(例如,下圖中d1的難樣品)。與用域數據對基線模型進行細化相比, 新提出的方法首先不需要額外的數據或推理時間(即簡單);其次充分利用難樣本挖掘,直接最佳化相似分布,以提高難樣本的效能(即有效);最後可以很容易地套用於解決廣泛的實際套用中的各種大差異,例如時尚商店中的化妝婦女、火車站的監視面孔、尋找失蹤老人或兒童的應用程式等。
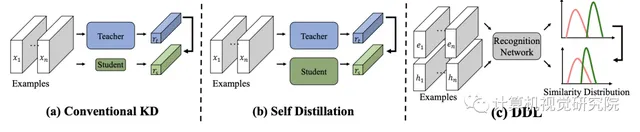
3、新方法分布式知識蒸餾損失( DDL )
首先看下不同知識蒸餾的差異:
Sampling Strategy from PE and PH
首先,我們介紹了在訓練過程中如何在一個小批中構造正負對的細節。給定來自PE和PH的兩種型別的輸入數據,每個小批由四個部份組成,兩種正對(即(x1,x2)∼PE和(x1,x2)∼PH),以及兩種具有不同身份的樣品(即x∼PE和x∼ PH)。
具體來說,一方面構造b正對(即2b樣本),另一方面構造b樣本,其身份與PE和PH不同。因此,在每個小批中有6b=(2b+b)∗2個樣品(更多細節見下圖)。
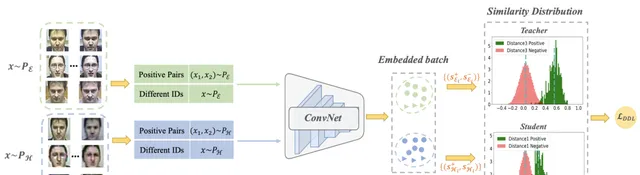
Positive Pairs
正對預先離線構建,每對由兩個具有相同身份的樣本組成。如上圖所示。每對正樣本按順序排列。透過深度網路F將數據嵌入到高維特征空間後,可以得到正對s+的相似性如下:
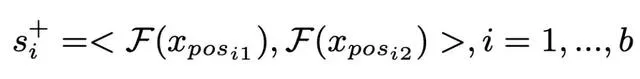
Negative Pairs
與Positive Pairs不同,透過難負樣本挖掘(hard negative mining)從具有不同身份的樣本中線上構造負對,選擇具有最大相似性的負對。具體而言,負對s−的相似性定義為:
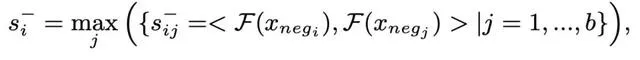
Similarity Distribution Estimation
相似分布估計的過程類似於[ Ustinova, E., Lempitsky, V.: Learning deep embeddings with histogram loss. In: NIPS. pp. 4170–4178 (2016) ],它是用一維直方圖進行的,用一個簡單的、分段可微的方式進行的,具有軟分配。具體來說,來自同一人的兩個樣本xi,xj形成一個正對,相應的標簽表示為mij=+1。相反,來自不同人員的兩個樣本形成一負對 ,標簽表示為mij=−1。然後得到兩個樣本集S和S−分別對應於正對和負對的相似性。
采用R維直方圖H+和H−,節點t1=-1,t2,...,tR=1均勻填充[−1,1]。然後,估計直方圖H在每個bin的值hr+為:
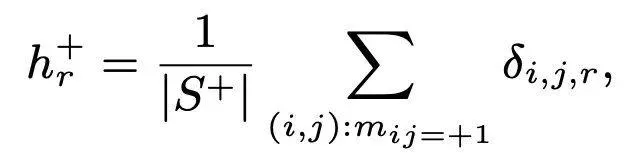
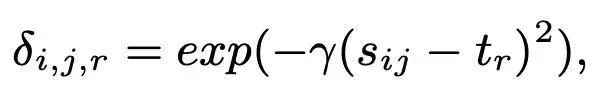
Distribution Distillation Loss
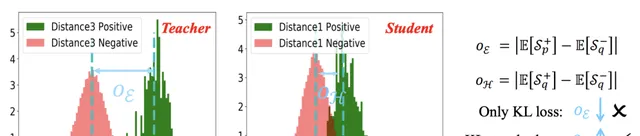
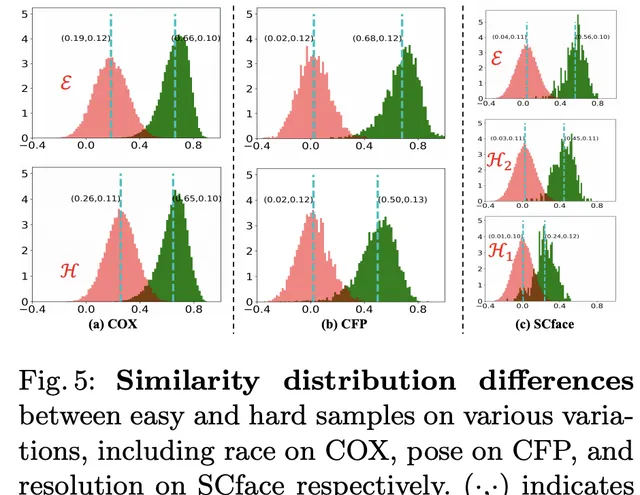
利用SotA人臉辨識引擎,從兩種樣本中獲得相似分布:簡單樣本和難樣本。在這裏,簡單樣本表明FR引擎表現良好,其中正對和負對的相似性分布被清楚地分離(見上圖中的教師分布),雖然難樣本表明FR引擎效能差,其中相似分布可能高度重疊(見上圖中的學生分布)。
KL散度損失
為了縮小簡單樣本和難樣本之間的效能差距,將難樣本的相似性分布(即學生分布)約束為近似簡單樣本的相似性分布(即教師分布)。教師分布由正對和負對的兩個相似分布組成,分別表示為P和P−。同樣,學生分布也由兩個相似分布組成,分別表示為Q和Q−。在以往KD方法的推動下,采用KL散度來約束學生和教師分布之間的相似性,定義如下:
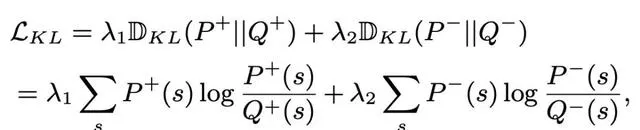
Order損失
然而,僅使用KL損失並不能保證良好的效能。事實上,教師分布可能選擇接近學生分布,導致正對和負對分布之間的更多混淆區域,這與論文的目標相反(見上圖)。
為了解決這個問題,設計了一個簡單而有效的術語,名為Order損失,它最小化了期望相似性分布之間的距離,從負對和正對控制重疊。提出的Order損失可以制定如下:
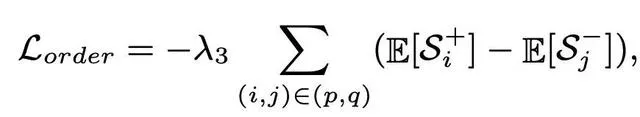
最後DDL損失為:
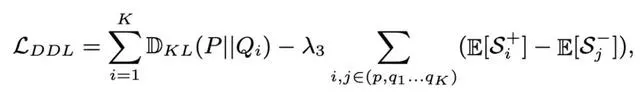
關於各種變化的概括
接下來,我們討論了DDL在各種變化上的推廣,它定義了我們的套用場景,以及我們如何選擇簡單/難樣本。基本上,我們可以根據影像是否包含可能阻礙身份資訊的大的面部變化來區分容易和難樣本,例如低分辨率和大姿態變化。
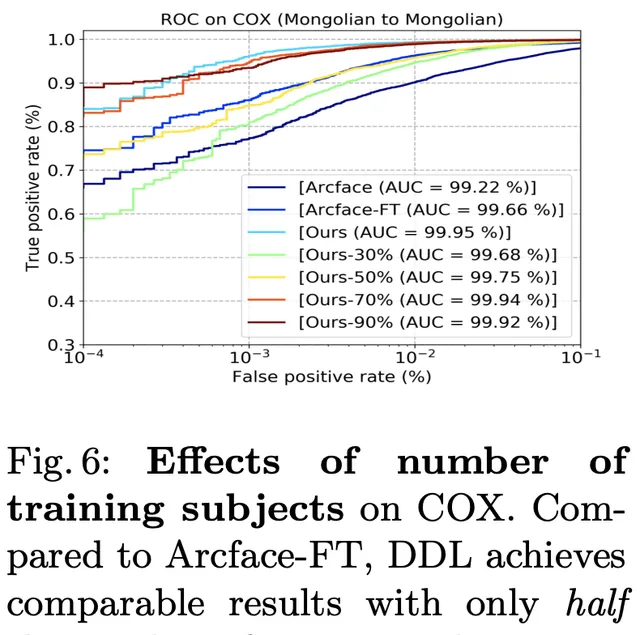
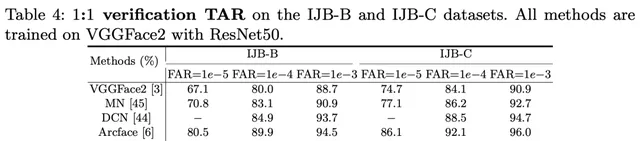
實驗
result

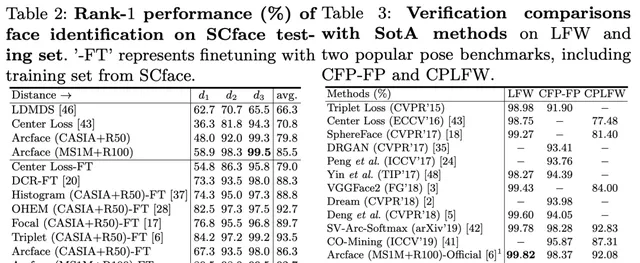
與以往的難樣本挖掘方法不同,在訓練過程中,基於損失值挖掘難樣本時,根據人類先驗預先定義難樣本。懲罰單個樣本或三胞胎,就像以前的難樣本挖掘方法一樣,並不能充分利用對總體分布的上下文洞察力。
DDL最大限度地減少了簡單樣本和難樣本之間全域相似性分布的差異,這對於處理難樣本和對雜訊樣本更具有魯棒性。「global」一詞意味著提出的方法利用了對小批中總體分布的足夠的上下文洞察力,而不是專註於樣本。
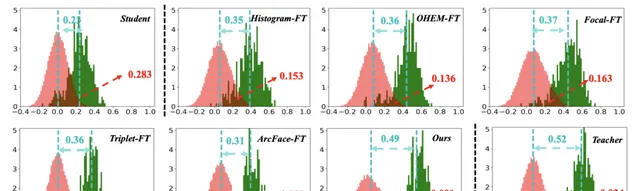
上圖說明了各種SotA方法的估計相似性分布。為了量化這些方法之間的差異,引入了兩個統計數據來進行評估,即expectation margin和histogram interp,即:
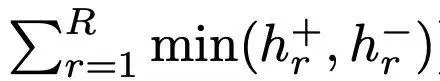
通常,較小的直方圖交集和較大的expectation margin
表示更好的驗證/辨識效能,因為這意味著[
Ustinova, E., Lempitsky, V.: Learning deep embeddings with histogram loss. In: NIPS. pp. 4170–4178 (2016)
]學習更多的判別嵌入。DDL實作了最接近教師分布的統計,從而獲得了最佳的效能。
END
轉載請聯系本公眾號獲得授權
電腦視覺研究院學習群等你加入!
ABOUT
電腦視覺研究院
電腦視覺研究院主要涉及深度學習領域,主要致力於目標檢測、目標跟蹤、影像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的論文演算法新框架,提供論文一鍵下載,並分享實戰計畫。研究院主要著重」技術研究「和「實踐落地」。研究院會針對不同領域分享實踐過程,讓大家真正體會擺脫理論的真實場景,培養愛動手編程愛動腦思考的習慣!
🔗











